
Jetty 与 Tomcat
Tomcat 的关键指标有吞吐量、响应时间、错误数、线程池、CPU 以及 JVM 内存
线程池中的线程数量不足会影响吞吐量和响应时间;
但是线程数太多会耗费大量 CPU;
当内存不足时会触发频繁地 GC,耗费 CPU;
Tomcat 中的关键的性能指标以及如何监控这些指标:主要有吞吐量、响
应时间、错误数、线程池、CPU 以及 JVM 内存。
在实际工作中,我们需要通过观察这些指标来诊断系统遇到的性能问题,找到性能瓶颈。如果我们监控到 CPU 上升,这时我们可以看看吞吐量是不是也上升了,如果是那说明正常;如果不是的话,可以看看 GC 的活动,如果 GC 活动频繁,并且内存居高不下,基本可以断定是内存泄漏。
线程池大小 = 每秒请求数 × 平均请求处理时间
这是理想的情况,也就是说线程一直在忙着干活,没有被阻塞在 I/O 等待上。实际上任务
在执行中,线程不可避免会发生阻塞,比如阻塞在 I/O 等待上,等待数据库或者下游服务
的数据返回,虽然通过非阻塞 I/O 模型可以减少线程的等待,但是数据在用户空间和内核
空间拷贝过程中,线程还是阻塞的。线程一阻塞就会让出 CPU,线程闲置下来,就好像工
作人员不可能 24 小时不间断地处理客户的请求,解决办法就是增加工作人员的数量,一个人去休息另一个人再顶上。对应到线程池就是增加线程数量,因此 I/O 密集型应用需要设置更多的线程.
请问工作中你如何监控 Web 应用的健康状态?
1先查看日志,那些方法耗时较大,用阿里爸爸开源arthas监控有问题的方法,排查问题
2 使用prometheus + grafana 监控各种指标,每天上班前看一下昨天的情况,设置好阈
值,如果达到就报警
3 监控系统会每隔一段时间,ping下我们系统,我们系统会pong回监控系统,并带上ip地
址,jvm当前使用率,cpu使用率等信息,如果超过一定数值,监控系统就会发出预警信
息,我们就需要去生产管理通过日志和命令查看,到底出了什么问题
遇到性能问题的时候是如何做问题定位的呢?
站在设计者的角度想问题?
假如让你来设计并实现一个 Web 容器,你会怎么做呢?
如何合理设计顶层模块?
如何考虑方方面面的需求,比如
最基本的功能需求是加载和运行 Web 程序,
最重要的非功能需求是高性能、高并发。
有意识地训练自己独立设计一个系统的能力。
学习新技术的小经验:在学习一门技术的时候,一定要先看清它的全貌,我推荐先看官方文档,看看都有哪些模块、整体上是如何设计的。接着我们先不要直接看源码,而是要动手跑一跑官网上的例子,或者用这个框架实现一个小系统,关键是要学会怎么使用。只有在这个基础上,才能深入到特定模块,去研究设计思路,或者深入到某一模块源码之中。这样在学习的过程中,按照一定的顺序一步一步来,就能够即时获得成就感,有了成就感你才会更加专注,才会愿意花更多时间和精力去深入研究。
第一个是我们需要带着明确的目标去学习。
第二个是一定要动手实践。另外适当的动手实践能够树立起信心,培养起兴趣,这
跟玩游戏上瘾有点类似,通过打怪升级,一点点积累起成就感。
问题:不是很明白线程sleep时间越长,为什么tomcat启动的线程就越多
回复: 这是Tomcat需要从线程池拿出一个工作线程来处理请求,请求处理(休眠)的时间越长,这些线程被阻塞,休眠时间越长,被阻塞的线程越多,这些线程无法被线程池回收,Tomcat线程池不得不创建更多的线程来处理新的请求。
Jetty 也是一个“HTTP 服务器+ Servlet 容器
Jetty 整体架构
简单来说,Jetty Server 就是由多个 Connector(连接器)、多个 Handler(处理器),
以及一个线程池组成。整体结构请看下面这张图。
Jetty Server 可以有多个 Connector 在不同的端口上监听客户请求。
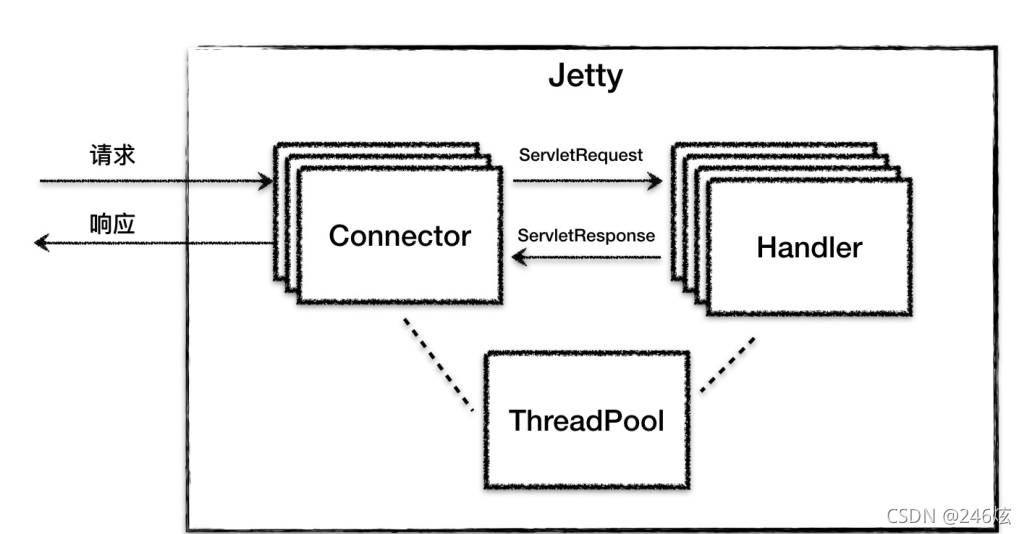
对比一下 Tomcat的整体架构,两者非常的相像。
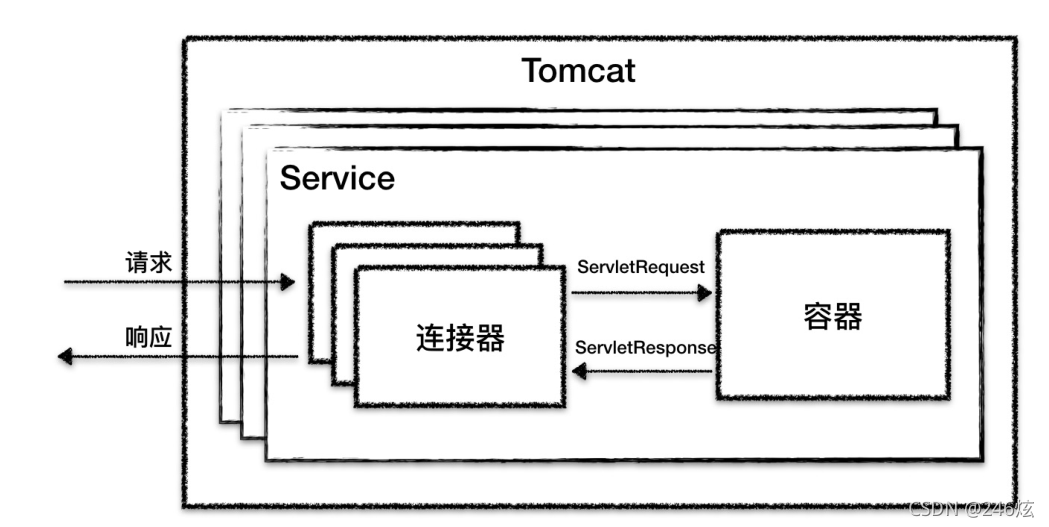
区别:
第一个区别是 Jetty 中没有 Service 的概念,Tomcat 中的 Service 包装了多个连接器和
一个容器组件,一个 Tomcat 实例可以配置多个 Service,不同的 Service 通过不同的连接
器监听不同的端口;而 Jetty 中 Connector 是被所有 Handler 共享的。
它们的第二个区别是,在 Tomcat 中每个连接器都有自己的线程池,而在 Jetty 中所有的
Connector 共享一个全局的线程池。
Jetty是基于NIO的模型来进行架构设计。
服务端在 I/O 通信上主要完成了三件事情:
监听连接、I/O 事件查询以及数据读写。
因此 Jetty 设计了Acceptor、SelectorManager和 Connection 来分别做这三件事情。
Acceptor
通过阻塞的方式来接受连接,这一点跟 Tomcat 也是一样的。
通过阻塞的方式来接受连接,这一点跟 Tomcat 也是一样的。public void accept(int acceptorID) throws IOException
{ServerSocketChannel serverChannel = _acceptChannel;if (serverChannel != null && serverChannel.isOpen()){// 这里是阻塞的SocketChannel channel = serverChannel.accept();// 执行到这里时说明有请求进来了accepted(channel);}
}SelectorManager
SelectorManager上面这两个过程是什么意思呢?
打个比方,你到餐厅吃饭,先点菜(注册 I/O 事件),服务员(ManagedSelector)给你一个单子(SelectionKey),等菜做好了(I/O 事件到了),服务员根据单子就知道是哪桌点了这个菜,于是喊一嗓子某某桌的菜做好了(调用了绑定在 SelectionKey 上的EndPoint 的方法)。
Connection
这个 Runnable 是 EndPoint 的一个内部类,它会调用 Connection 的回调方法来处理请
求。Jetty 的 Connection 组件类比就是 Tomcat 的 Processor,负责具体协议的解析,得
到 Request 对象,并调用 Handler 容器进行处理。
这段代码就是告诉 EndPoint,数据到了你就调我这些回调方法 _readCallback 吧,有点异
步 I/O 的感觉,也就是说 Jetty 在应用层面模拟了异步 I/O 模型。而在回调方法 _readCallback 里,会调用 EndPoint 的接口去读数据,读完后让 HTTP 解析器去解析字节流,HTTP 解析器会将解析后的数据,包括请求行、请求头相关信息存到Request 对象里。
响应处理:Connection 调用 Handler 进行业务处理,Handler 会通过 Response 对象来操作响应流,向流里面写入数据,HttpConnection 再通过 EndPoint 把数据写到
Channel,这样一次响应就完成了。
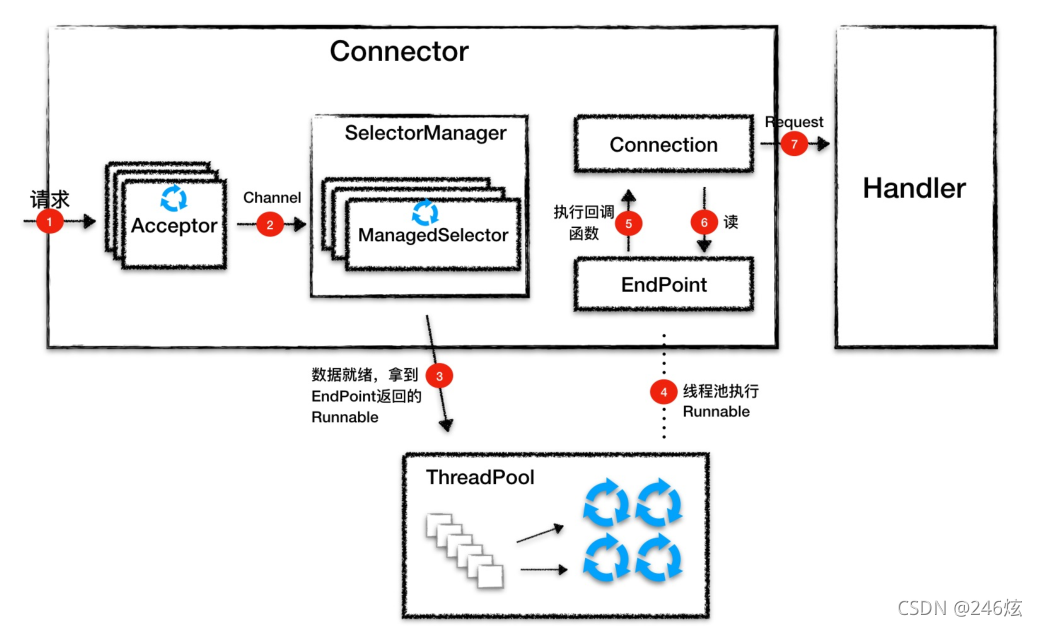
1.Acceptor 监听连接请求,当有连接请求到达时就接受连接,一个连接对应一个
Channel,Acceptor 将 Channel 交给 ManagedSelector 来处理。
2.ManagedSelector 把 Channel 注册到 Selector 上,并创建一个 EndPoint 和
Connection 跟这个 Channel 绑定,接着就不断地检测 I/O 事件。
3.I/O 事件到了就调用 EndPoint 的方法拿到一个 Runnable,并扔给线程池执行。
线程池中调度某个线程执行 Runnable。
5.Runnable 执行时,调用回调函数,这个回调函数是 Connection 注册到 EndPoint 中
的。
回调函数内部实现,其实就是调用 EndPoint 的接口方法来读数据。
7.Connection 解析读到的数据,生成请求对象并交给 Handler 组件去处理
问题:分在不同的线程里我认为是这样分工明确好比工厂流水线最大化提升处理能力。
我有个疑问是用全局线程池真的好吗,不是应该根据任务类型分配线程池的吗?用全局的
不会互相干扰吗?
回复: 全局线程池和多个隔离的线程池各有优缺点。全局的线程池方便控制线程总数,防止过多的线程导致大量线程切换。隔离的线程池可以控制任务优先级,确保低优先级的任务不会去抢高优先级任务的线程。
问题:感觉jetty就是一个netty模型
回复:说的很对,Tomcat和Jetty相比,Jetty的I/O线程模型更像Netty,Jetty的EatWhatYouKill线程策略,其实就是Netty 4.0中的线程模型。
Jetty和Tomcat没有本质区别,一般来说Jetty比较小巧,又可以高度裁剪和定制,因此适合放在嵌入式设备等对内存资源比较紧张的场合。而Tomcat比较成熟稳定,对企业级应用支持比较好
问题:Jetty作为后起之秀,跟tomcat相比,它的优势在哪儿?他们的设计思路不同,我们自己在设计的时候应该依据什么来确定使用哪种呢?
回复: Jetty的优势是小巧,代码量小,比如它只支持非阻塞IO,这意味着把它加载到内存后占用内存空间也小,另外还可以把它裁剪的更小,比如不需要Session支持,可以方便的去掉相应的Hanlder。
问题:跑在不同的线程里是为了解耦么?实在想不出,告诉答案吧??
回复: 反过来想,如果等待连接到达,接收连接、等待数据到达、数据读取和请求处理(等待应用处理完)都在一个线程里,这中间线程可能大部分时间都在”等待“,没有干活,而线程资源是很宝贵的。并且线程阻塞会发生线程上下文切换,浪费CPU资源。
acceptor、connector和sellector各自承担不同工作,用不同线程执行,
1.用异步和通知机制,效率更高
2.一个线程干一个事,代码实现更加简单
3.更容易定位和分析故障
Jetty架构之Handler组件
Connector 会将 Servlet 请求交给Handler 去处理,那 Handler 又是如何处理请求的呢
Handler 是什么??
Handler 就是一个接口,它有一堆实现类,Jetty 的 Connector 组件调用这些接口来处理
Servlet 请求,我们先来看看这个接口定义成什么样子。
public interface Handler extends LifeCycle, Destroyable
{// 处理请求的方法public void handle(String target, Request baseRequest, HttpServletRequest request, throws IOException, ServletException;// 每个 Handler 都关联一个 Server 组件,被 Server 管理public void setServer(Server server);public Server getServer();// 销毁方法相关的资源public void destroy();
}
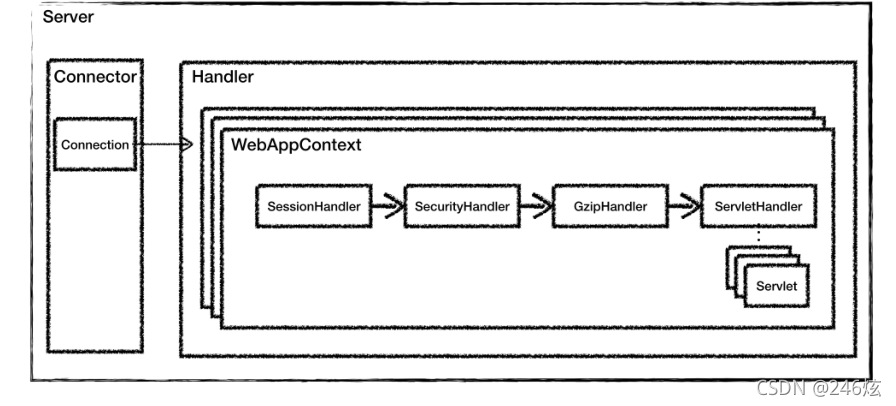
Jetty Server 就是由多个 Connector、多个 Handler,以及一个线程池组成。
Jetty 的 Handler 设计是它的一大特色,Jetty 本质就是一个 Handler 管理器,Jetty 本身
就提供了一些默认 Handler 来实现 Servlet 容器的功能,你也可以定义自己的 Handler 来
添加到 Jetty 中,这体现了“微内核 + 插件”的设计思想。
总结: 从Tomcat和Jetty中 学习到的 组件化设计规范
当我们学习一门技术的时候,如果可以勤于思考、善于总结,可以帮助我们看到现象背 后更本质的东西,让我们在成长之路上更快“脱颖而出
组件化及可配置
那 Web 容器如何实现这种组件化设计呢?
有两个要点:
第一个是面向接口编程。我们需要对系统的功能按照“高内聚、低耦合”的原则进行拆
分,每个组件都有相应的接口,组件之间通过接口通信,这样就可以方便地替换组件了。
比如我们可以选择不同连接器类型,只要这些连接器组件实现同一个接口就行。
第二个是 Web 容器提供一个载体把组件组装在一起工作。组件的工作无非就是处理请
求,因此容器通过责任链模式把请求依次交给组件去处理。对于用户来说,我只需要告诉
Web 容器由哪些组件来处理请求。把组件组织起来需要一个“管理者”,这就是为什么
Tomcat 和 Jetty 都有一个 Server 的概念,Server 就是组件的载体,Server 里包含了连
接器组件和容器组件;容器还需要把请求交给各个子容器组件去处理,Tomcat 和 Jetty
都是责任链模式来实现的。
用户通过配置来组装组件,跟 Spring 中 Bean 的依赖注入相似。Spring 的用户可以通过
配置文件或者注解的方式来组装 Bean,Bean 与 Bean 的依赖关系完全由用户自己来定
义。这一点与 Web 容器不同,Web 容器中组件与组件之间的关系是固定的,比如
Tomcat 中 Engine 组件下有 Host 组件、Host 组件下有 Context 组件等,但你不能在
Host 组件里“注入”一个 Wrapper 组件,这是由于 Web 容器本身的功能来决定的。
组件的创建。
由于组件是可以配置的,Web 容器在启动之前并不知道要创建哪些组件,也就是说,不能
通过硬编码的方式来实例化这些组件,而是需要通过反射机制来动态地创建。具体来说,
Web 容器不是通过 new 方法来实例化组件对象的,而是通过 Class.forName 来创建组
件。无论哪种方式,在实例化一个类之前,Web 容器需要把组件类加载到 JVM,这就涉及
一个类加载的问题,Web 容器设计了自己类加载器。
问题:Spring 也是通过反射机制来动态地实例化 Bean,那么它用到的类加载器是从哪里来的呢?
Web 容器给每个 Web 应用创建了一个类加载器,Spring 用到的类加载器是 Web 容
器传给它的。
Tomcat 和 Jetty 都采用了类似的办法来管理组件的生命周期,主要有两个要点,
一是父组件负责子组件的创建、启停和销毁。这样只要启动最上层组件,整个 Web 容器就被启动起来了,也就实现了一键式启停;
二是 Tomcat 和 Jetty 都定义了组件的生命周期状态,并且把组件状态的转变定义成一个事件,一个组件的状态变化会触发子组件的变化,比如 Host容器的启动事件里会触发 Web 应用的扫描和加载,最终会在 Host 容器下创建相应的Context 容器,而 Context 组件的启动事件又会触发 Servlet 的扫描,进而创建 Wrapper组件。
那么如何实现这种联动呢?
答案是观察者模式。具体来说就是创建监听器去监听容器的状态变化,在监听器的方法里去实现相应的动作,这些监听器其实是组件生命周期过程中的“扩展点”。
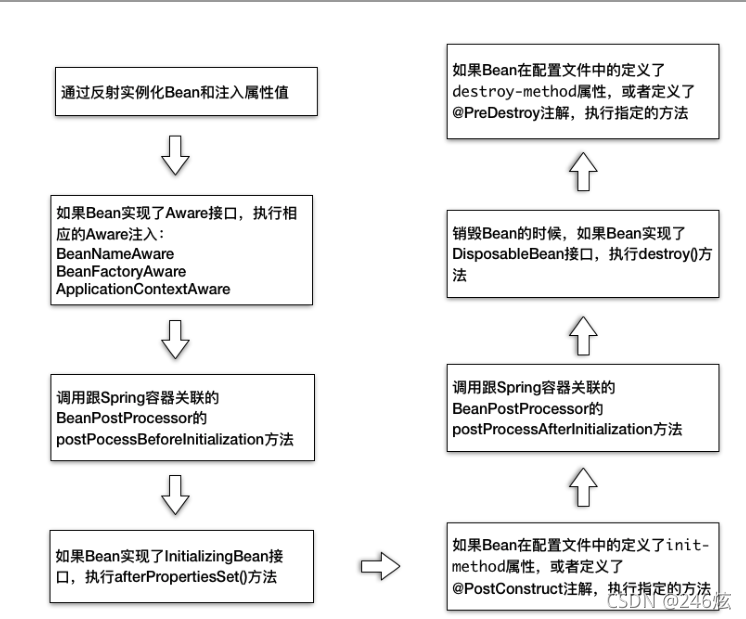
Spring 也采用了类似的设计,Spring 给 Bean 生命周期状态提供了很多的“扩展点”。这
些扩展点被定义成一个个接口,只要你的 Bean 实现了这些接口,Spring 就会负责调用这
些接口,这样做的目的就是,当 Bean 的创建、初始化和销毁这些控制权交给 Spring 后,
Spring 让你有机会在 Bean 的整个生命周期中执行你的逻辑。下面我通过一张图帮你理解
Spring Bean 的生命周期过程。
回复: 如果业务处理时间过长,阻塞大量Tomcat线程导致线程饥饿,可以考虑异步Servlet,这样Tomcat线程立即返回,耗时处理由业务线程来处理。
但业务线程同样有线程阻塞的问题,比如阻塞在IO上。基本思路都是用“异步回调”来避免阻塞,采用异步非阻塞IO模型,用少量线程通过事件循环来提高吞吐量。Spring给出的方案是Spring Webflux。Nodejs也是这样,适合IO密集型的应用。
协程也是这个思路,并且它的网络通信也是通过epoll来实现非阻塞的,只不过它向开发者提供了“同步阻塞”式的API,另外协程的上下文切换开销也比线程小,因为它将“函数调用上下文”保存在应用层面,内核感觉不到,但是这需要额外的内存、调度和管理开销。
什么是进程和线程?
这是基于安全上的考虑,用户程序只能访问用户空间,内核程序可以访问整个进程空间,并且只有内核可以直接访问各种硬件资源,比如磁盘和网卡。那用户程序需要访问这些硬件资源该怎么办呢?答案是通过系统调用,系统调用可以理解为内核实现的函数,比如应用程序要通过网卡接收数据,会调用 Socket 的 read 函数。
在 Linux 中,线程是一个轻量级的进程,轻量级说的是线程只是一个 CPU 调度单元,因此
线程有自己的task_struct结构体和运行栈区,但是线程的其他资源都是跟父进程共用
的,比如虚拟地址空间、打开的文件和 Socket 等。
用户态和用户空间是啥关系?
回复: 你可以理解为CPU上有个开关,可以设置CPU的工作模式:用户态和内核态。在用户态模式下访问用户空间,也就是低地址的3GB。
什么是虚拟内存和物理内存?
什么是用户空间和内核空间??
线程的阻塞到底意味着什么?
内核又是如何唤醒用户线程的等等这些问题?
大体来说,Tomcat 的核心竞争力是成熟稳定,因为它经过了多年的市场考验,应用也相当广泛,对于比较复杂的企业级应用支持得更加全面。也因为如此,Tomcat 在整体结构上比 Jetty 更加复杂,功能扩展方面可能不如 Jetty 那么方便。
而 Jetty 比较年轻,设计上更加简洁小巧,配置也比较简单,功能也支持方便地扩展和裁
剪,比如我们可以把 Jetty 的 SessionHandler 去掉,以节省内存资源,因此 Jetty 还可以
运行在小型的嵌入式设备中,比如手机和机顶盒。当然,我们也可以自己开发一个
Handler,加入 Handler 链中用来扩展 Jetty 的功能。值得一提的是,Hadoop 和 Solr 都
嵌入了 Jetty 作为 Web 服务器.
从设计的角度来看,Tomcat 的架构基于一种多级容器的模式.
Tomcat 线程池调优大法,可以延伸 java 的线程池调优
线程池的调优就是设置合理的线程池参数。
Tomcat 线程池中有哪些关键参数:
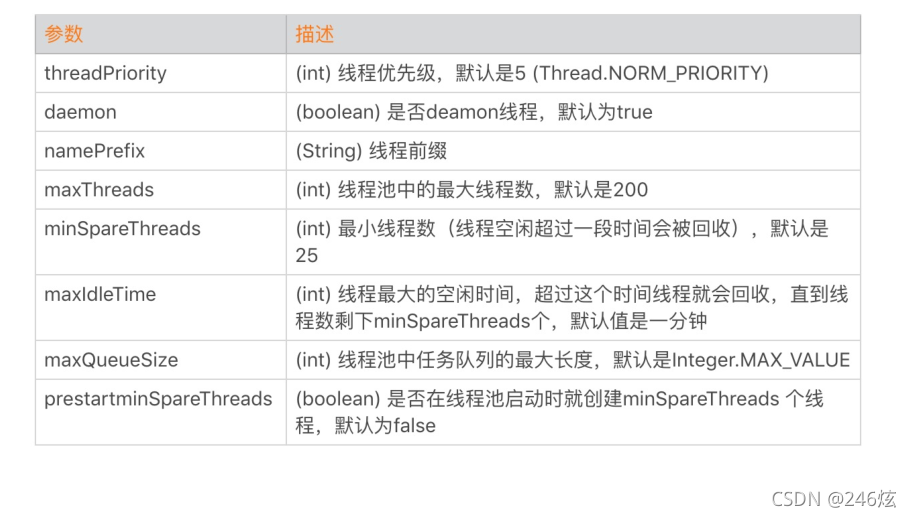
这里面最核心的就是如何确定 maxThreads 的值
如果这个参数设置小了,Tomcat 会发生线程饥饿,并且请求的处理会在队列中排队等待,导致响应时间变长;如果maxThreads 参数值过大,同样也会有问题,因为服务器的 CPU 的核数有限,线程数太多会导致线程在 CPU 上来回切换,耗费大量的切换开销
设置小了,队列中排队等待
设置大了,发生来回的CPU切换
利特尔法则
系统中的请求数 = 请求的到达速率 × 每个请求处理时间
因此可以总结出一个公式
线程池大小 = 每秒请求数 × 平均请求处理时间
这是理想的情况,也就是说线程一直在忙着干活,没有被阻塞在 I/O 等待上。实际上任务
在执行中,线程不可避免会发生阻塞,比如阻塞在 I/O 等待上,等待数据库或者下游服务
的数据返回,虽然通过非阻塞 I/O 模型可以减少线程的等待,但是数据在用户空间和内核
空间拷贝过程中,线程还是阻塞的。线程一阻塞就会让出 CPU,线程闲置下来,就好像工
作人员不可能 24 小时不间断地处理客户的请求,解决办法就是增加工作人员的数量,一个人去休息另一个人再顶上。对应到线程池就是增加线程数量,因此 I/O 密集型应用需要设置更多的线程。
线程 I/O 时间与 CPU 时间
至此我们又得到一个线程池个数的计算公式,假设服务器是单核的。
线程池大小 = (线程 I/O 阻塞时间 + 线程 CPU 时间 )/ 线程 CPU 时间
其中:线程 I/O 阻塞时间 + 线程 CPU 时间 = 平均请求处理时间。
对比一下两个公式,你会发现,平均请求处理时间在两个公式里都出现了,这说明请求时间越长,需要更多的线程是毫无疑问的。
不同的是第一个公式是用每秒请求数来乘以请求处理时间;而第二个公式用请求处理时间来除以线程 CPU 时间,请注意 CPU 时间是小于请求处理时间的。
虽然这两个公式是从不同的角度来看待问题的,但都是理想情况,都有一定的前提条件。
请求处理时间越长,需要的线程数越多,但前提是 CPU 核数要足够,如果一个 CPU来支撑 10000 TPS 并发,创建 10000 个线程,显然不合理,会造成大量线程上下文切换。
请求处理过程中,I/O 等待时间越长,需要的线程数越多,前提是 CUP 时间和 I/O 时间的比率要计算的足够准确。
请求进来的速率越快,需要的线程数越多,前提是 CPU 核数也要跟上。
实际场景下如何确定线程数??
那么在实际情况下,线程池的个数如何确定呢?这是一个迭代的过程,先用上面两个公式大概算出理想的线程数,再反复压测调整,从而达到最优。
一般来说,如果系统的 TPS 要求足够大,用第一个公式算出来的线程数往往会比公式二算
出来的要大。我建议选取这两个值中间更靠近公式二的值。也就是先设置一个较小的线程
数,然后进行压测,当达到系统极限时(错误数增加,或者响应时间大幅增加),再逐步加大线程数,当增加到某个值,再增加线程数也无济于事,甚至 TPS 反而下降,那这个值可以认为是最佳线程数。
线程池中其他的参数,最好就用默认值,能不改就不改,除非在压测的过程发现了瓶颈。如果发现了问题就需要调整,比如 maxQueueSize,如果大量任务来不及处理都堆积在
maxQueueSize 中,会导致内存耗尽,这个时候就需要给 maxQueueSize 设一个限制。
当然,这是一个比较极端的情况了。
再比如 minSpareThreads 参数,默认是 25 个线程,如果你发现系统在闲的时候用不到
25 个线程,就可以调小一点;如果系统在大部分时间都比较忙,线程池中的线程总是远远
多于 25 个,这个时候你就可以把这个参数调大一点,因为这样线程池就不需要反复地创建和销毁线程了。
总结:Tomcat 线程池的各种参数,其中最重要的参数是最大线程数 maxThreads。
理论上我们可以通过利特尔法则或者 CPU 时间与 I/O 时间的比率,计算出一个理想值,这
个值只具有指导意义,因为它受到各种资源的限制,实际场景中,我们需要在理想值的基础上进行压测,来获得最佳线程数。
业务的目标是什么?现在的情况是什么?
问题:其实调优很多时候都是在找系统瓶颈,假如有个状况:系统响应比较慢,但 CPU 的用率不高,内存有所增加,通过分析 Heap Dump 发现大量请求堆积在线程池的队列中,请问这种情况下应该怎么办呢?
回复: 这种情况应该怀疑大量线程被阻塞了,应该看看web应用是不是在访问外部数据库或者外部服务遇到了延迟。
回复: 查看调用的服务是不是耗时太长。
哪些原因可能导致 JVM 抛出 OutOfMemoryError 异常吗?
JVM 在抛出 java.lang.OutOfMemoryError 时,除了会打印出一行描述信息,还会打印堆
栈跟踪,因此我们可以通过这些信息来找到导致异常的原因。在寻找原因前,我们先来看看有哪些因素会导致 OutOfMemoryError,其中内存泄漏是导致 OutOfMemoryError 的一
个比较常见的原因。
内存溢出场景及方案
java.lang.OutOfMemoryError: Java heap space
JVM 无法在堆中分配对象时,会抛出这个异常,导致这个异常的原因可能有三种:
内存泄漏。Java 应用程序一直持有 Java 对象的引用,导致对象无法被 GC 回收,比如
对象池和内存池中的对象无法被 GC 回收。
配置问题。有可能是我们通过 JVM 参数指定的堆大小(或者未指定的默认大小),对于应用程序来说是不够的。解决办法是通过 JVM 参数加大堆的大小。
.finalize 方法的过度使用。如果我们想在 Java 类实例被 GC 之前执行一些逻辑,比如清
理对象持有的资源,可以在 Java 类中定义 finalize 方法,这样 JVM GC 不会立即回收这些对象实例,而是将对象实例添加到一个叫“java.lang.ref.Finalizer.ReferenceQueue”的
队列中,执行对象的 finalize 方法,之后才会回收这些对象。Finalizer 线程会和主线程竞
争 CPU 资源,但由于优先级低,所以处理速度跟不上主线程创建对象的速度,因此
ReferenceQueue 队列中的对象就越来越多,最终会抛出 OutOfMemoryError。解决办法
是尽量不要给 Java 类定义 finalize 方法。
网络通信方面的错误和异常
网络通信方面的错误和异常也是我们在实际工作中经常碰到的,
需要理解异常背后的原理,才能更快更精准地定位问题,从而找到解决办法。
Java Socket 网络编程常见的异常有哪些
常见异常
java.net.SocketTimeoutException
指超时错误。
超时分为连接超时和读取超时,
连接超时是指在调用 Socket.connect 方法的时候超时,
而读取超时是调用 Socket.read 方法时超时。
请你注意的是,连接超时往往是由于网络不稳定造成的,
但是读取超时不一定是网络延迟造成的,很有可能是下游服务的响应时间过长。
java.net.BindException: Address already in use: JVM_Bind
指端口被占用。当服务器端调用 new ServerSocket(port) 或者 Socket.bind 函数时,如果
端口已经被占用,就会抛出这个异常。我们可以用netstat –an命令来查看端口被谁占用
了,换一个没有被占用的端口就能解决。
java.net.ConnectException: Connection refused: connect
指连接被拒绝。当客户端调用 new Socket(ip, port) 或者 Socket.connect 函数时,可能
会抛出这个异常。原因是指定 IP 地址的机器没有找到;或者是机器存在,但这个机器上没
有开启指定的监听端口。
解决办法是从客户端机器 ping 一下服务端 IP,假如 ping 不通,可以看看 IP 是不是写错
了;假如能 ping 通,需要确认服务端的服务是不是崩溃了。
java.net.SocketException: Socket is closed
指连接已关闭。出现这个异常的原因是通信的一方主动关闭了 Socket 连接(调用了
Socket 的 close 方法),接着又对 Socket 连接进行了读写操作,这时操作系统会
报“Socket 连接已关闭”的错误。
java.net.SocketException: Connection reset/Connect reset by peer: Socket write error
指连接被重置。这里有两种情况,分别对应两种错误:
第一种情况是通信的一方已经将Socket 关闭,可能是主动关闭或者是因为异常退出,这时如果通信的另一方还在写数据,就会触发这个异常(Connect reset by peer);如果对方还在尝试从 TCP 连接中读数据,则会抛出 Connection reset 异常。
为了避免这些异常发生,在编写网络通信程序时要确保:
程序退出前要主动关闭所有的网络连接。
检测通信的另一方的关闭连接操作,当发现另一方关闭连接后自己也要关闭该连接。
java.net.SocketException: Broken pipe
指通信管道已坏。发生这个异常的场景是,通信的一方在收到“Connect reset by peer:
Socket write error”后,如果再继续写数据则会抛出 Broken pipe 异常,解决方法同上。
java.net.SocketException: Too many open files
指进程打开文件句柄数超过限制。当并发用户数比较大时,服务器可能会报这个异常。这是因为每创建一个 Socket 连接就需要一个文件句柄,此外服务端程序在处理请求时可能也需要打开一些文件。
你可以通过lsof -p pid命令查看进程打开了哪些文件,是不是有资源泄露,也就是说进
程打开的这些文件本应该被关闭,但由于程序的 Bug 而没有被关闭。
如果没有资源泄露,可以通过设置增加最大文件句柄数。具体方法是通过ulimit -a来查
看系统目前资源限制,通过ulimit -n 10240修改最大文件数。
Tomcat 网络参数
接下来我们看看 Tomcat 两个比较关键的参数:maxConnections 和 acceptCount。
在解释这个参数之前,先简单回顾下 TCP 连接的建立过程:客户端向服务端发送 SYN 包,服务端回复 SYN+ACK,同时将这个处于 SYN_RECV 状态的连接保存到半连接队列。客户端返回 ACK 包完成三次握手,服务端将 ESTABLISHED 状态的连接移入accept 队列,等待应用程序(Tomcat)调用 accept 方法将连接取走。
这里涉及两个队列:
半连接队列:保存 SYN_RECV 状态的连接。队列长度由net.ipv4.tcp_max_syn_backlog设置。
accept 队列:保存 ESTABLISHED 状态的连接。队列长度为min(net.core.somaxconn,backlog)。其中 backlog 是我们创建 ServerSocket 时指定的参数,最终会传递给 listen 方法:
int listen(int sockfd, int backlog);如果我们设置的 backlog 大于net.core.somaxconn,accept 队列的长度将被设置为ne
t.core.somaxconn,而这个 backlog 参数就是 Tomcat 中的acceptCount参数,默认
值是 100,但请注意net.core.somaxconn的默认值是 128。
你可以想象在高并发情况下当 Tomcat 来不及处理新的连接时,这些连接都被堆积在 accept 队列中,而acceptCount参数可以控制 accept 队列的长度,超过这个长度时,内核会向客户端发送RST,这样客户端会触发上文提到的“Connection reset”异常。
而 Tomcat 中的maxConnections是指 Tomcat 在任意时刻接收和处理的最大连接数。当Tomcat 接收的连接数达到 maxConnections 时,Acceptor 线程不会再从 accept 队列中取走连接,这时 accept 队列中的连接会越积越多。
maxConnections 的默认值与连接器类型有关:NIO 的默认值是 10000,APR 默认是8192。
所以你会发现 Tomcat 的最大并发连接数等于maxConnections + acceptCount。
如果acceptCount 设置得过大,请求等待时间会比较长;
如果 acceptCount 设置过小,高并发情况下,客户端会立即触发 Connection reset 异常。
我们还分析了 Tomcat 中两个比较重要的参数:acceptCount 和maxConnections。acceptCount 用来控制内核的 TCP 连接队列长度,maxConnections用于控制 Tomcat 层面的最大连接数,我们通过调整 acceptCount 和相关的内核参数somaxconn,增加了系统的并发度。
我们通过netstat命令发现有大量的 TCP 连接处在 TIME_WAIT 状态,
请问这是为什么?它可能会带来什么样的问题呢?