
spark RDD中的并行度、分区器默认策略
源头RDD
源头RDD有自己的分区计算逻辑,一般没有分区器,并行度是根据分区算法自动计算的,RDD的compute函数中记录了数据如何而来,如何分区的
hadoopRDD,根据XxxinputFormat.getInputSplits()来决定,比如默认的TextInputFormat将文件按照0-128M进行切割,剩余部分是否小于128M的1.1倍
JdbcRDD,需要指定一个数字类型的字段,而且指定上界,下届,然后指定并行度进行分割
大部分源头RDD都有传入并行度的参数
有些源头rdd按照backend.defaultParallelism()获取默认并行度,比如sc.paralleize("a","b")
本地模式:getInt("spark.default.parallelism", totalCores),根据spark.default.parallelism参数,如果没配置就是机器的总逻辑核数,setMaster(local[*]) *代表全部逻辑核
集群模式:getInt("spark.default.parallelism", math.max(totalCoreCount.get(), 2)),根据spark.default.parallelism参数,如果没配置就是yarn的executor的总逻辑核数,最小也得两个并行度
窄依赖RDD
窄依赖RDD,没有自己的分区器(也可以设置为沿用父rdd的分区器),默认集成它的父RDD的并行度
有个特殊的窄依赖算子,coalesce(2,true),他需要指定并行度
宽依赖 RDD
宽依赖 RDD(ShuffledRDD),这种RDD是通过进行shuffle的算子得到的,shuffle算子必须要一个分区器,要么传,要么走默认分区器
指定并行度
shuffle算子指定并行度,groupBy(f(),4) //分区器为:hashpartitioner,并行度为4
有些特殊的shuffle算子,默认分区器不是hashpartitioner。比如sortBy(),他是RangePartitiner,但是sortBy其实用的是sortByKey然后取value 最终.values把分区器搞丢了
指定分区器
shuffle算子指定分区器,groupBy(f(),RangePartitioner(4)) //分区器为:RangePartitioner,并行度为4
默认分区器策略
按照 Partitioner.defaultPartitioner( )获取分区器
最大并行度:父RDD中并行度的最大值
默认并行度:spark.default.parallelism值,如果没设置这个参数,则取最大并行度
最大分区器:父RDD中并行度最大的分区器
有最大分区器,而且以下两个条件满足一个即可,此时沿用最大分区器
父 RDD 中的最大并行度/最大分区器所在RDD的并行度<10
或
默认并行度小于等于最大分区器所在rdd的并行度
没有最大分区器,默认以hashPatitioner作为分区器,并行度为默认并行度
例1
如果:rdd1:并行度500,分区器NONE,rdd2: 并行度100,分区器HashPartitioner
var rdd3 = rdd1.join(rdd2)
问:此时rdd3的分区器和并行度有多大?
最大并行度:父RDD中并行度的最大值=>500
默认并行度:取spark.default.parallelism值,如果没有则最大并行度=>500
最大分区器:父RDD中并行度最大的分区器=>HashPartitioner
判断能否沿用父RDD最大分区器
存在最大分区器(满足)
以下两个条件满足一个
最大并行度(500)/最大分区器所在RDD的并行度(100)<10 (满足)
或
默认并行度(500)小于等于 最大分区器所在rdd的并行度(100)(不满足)
因此可以沿用父RDD最大分区器,所以rdd3的分区器:Hashpartitioner,并行度100
例2
如果:rdd1:并行度2000,分区器None,rdd2: 并行度100,分区器HashPartitioner
var rdd3 = rdd1.join(rdd2)
问:此时rdd3的分区器和并行度有多大?
最大并行度:父RDD中并行度的最大值=>2000
默认并行度:取spark.default.parallelism值,如果没有则最大并行度=>2000
最大分区器:父RDD中并行度最大的分区器=>HashPartitioner
判断能否沿用父RDD最大分区器
存在最大分区器(满足)
以下两个条件满足一个
最大并行度(2000)/最大分区器所在RDD的并行度(100)<10 (不满足)
或
默认并行度(2000)小于等于 最大分区器所在rdd的并行度(2000)(不满足)
因此不可以沿用父RDD最大分区器,所以rdd3的分区器:采用默认的分区器、采用默认并行度HashPartitioner(2000)
例3
如果:rdd1:并行度2000,分区器None,rdd2: 并行度100,分区器HashPartitioner ,conf.set("spark.default.parallelism",100)
var rdd3 = rdd1.join(rdd2)
问:此时rdd3的分区器和并行度有多大?
最大并行度:父RDD中并行度的最大值=>2000
默认并行度:取spark.default.parallelism值,如果没有则最大并行度=>100
最大分区器:父RDD中并行度最大的分区器=>HashPartitioner
判断能否沿用父RDD最大分区器
存在最大分区器(满足)
以下两个条件满足一个
最大并行度(2000)/最大分区器所在RDD的并行度(100)<10 (不满足)
或
默认并行度(100)小于等于 最大分区器所在rdd的并行度(100)(满足)
因此可以沿用父RDD最大分区器,所以rdd3的分区器:Hashpartitioner,并行度100
关于是否Shuffle问题延申1
例1中rdd1.join(rdd2).reduceByKey()
问:此时reduceByKey操作会发生shuffle吗?
答案是不会,虽然reduceByKey产生的Dependency是ShuffleDependency,但是它的分区器和它父RDD的分区器是同一个分区器(沿用父RDD的分区器),所以不会有shuffle产生
关于是否Shuffle问题延申2
例1中rdd1.join(rdd2).repartition(100).reduceByKey()
问:此时reduceByKey操作会发生shuffle吗?
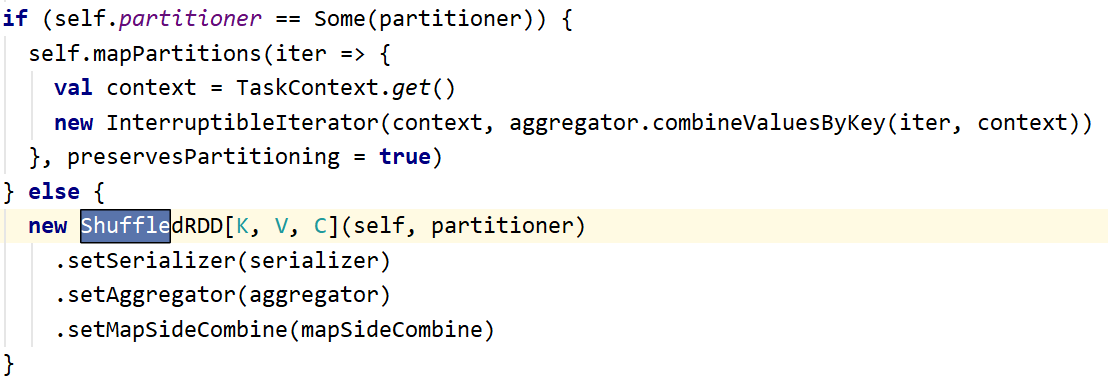
答案是会,按道理来说repartition(100)会产生一个Hashpartitioner(100),reduceByKey(),会沿用repartition产生的rdd的分区器,导致reduceByKey()不会产生shuffle,那为何还会有呢?
这个就是上边说的repartition算子中.values把分区器搞丢了
repartition其实是调用的coalesce(100,true)
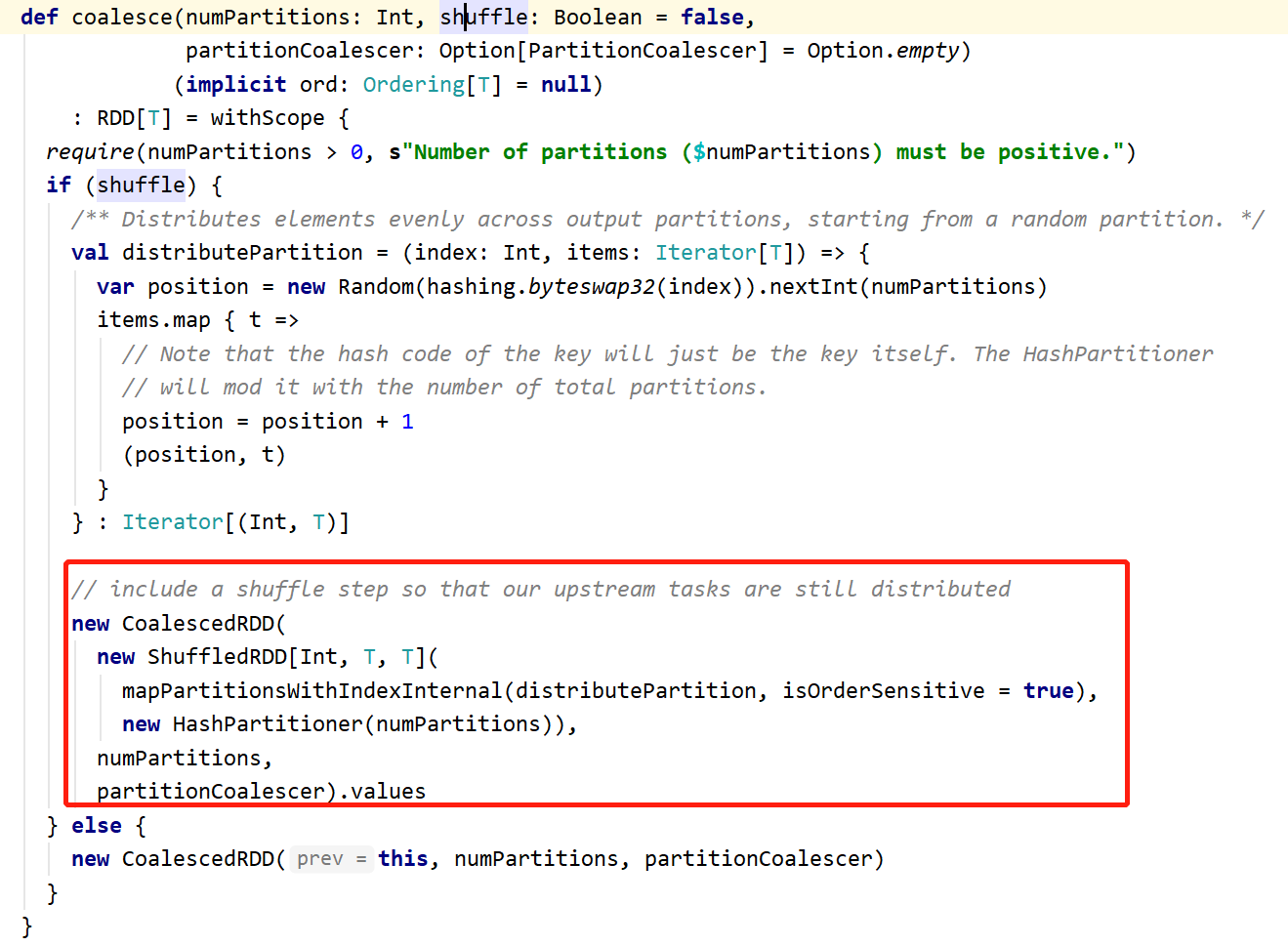
new CoalescedRDD(new ShuffledRDD).values
也就是说,一次repartition,产生了3个rdd
CoalescedRDD
ShuffledRDD
MapPartitionsRDD ----.value产生的相当于map取value,这是一个窄依赖,会把RDD[T]的分区器擦除掉,因此再进行reduceByKey的时候看似父节点有分区器,其实被repartition内部的RDD转换隐形擦除了,导致shuffle产生(上述sortBy也有这个问题)
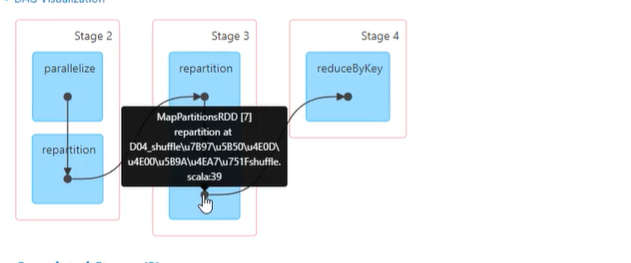
关于是否Shuffle问题延申3
问:rdd1.join(rdd2)什么情况下不发生shuffle?
当rdd1和rdd2以及join产生的新rdd采用相同的分区器,那么就不会产生shuffle
val rdd1:RDD[(String,Int)]rdda.partitionBy(new HashPartitioner(partitions 2))
val rdd2:RDD[(String,Int)]rddb.partitionBy(new HashPartitioner(partitions=2))
rdd1.join(rdd2,new HashPartitioner(partitions 2))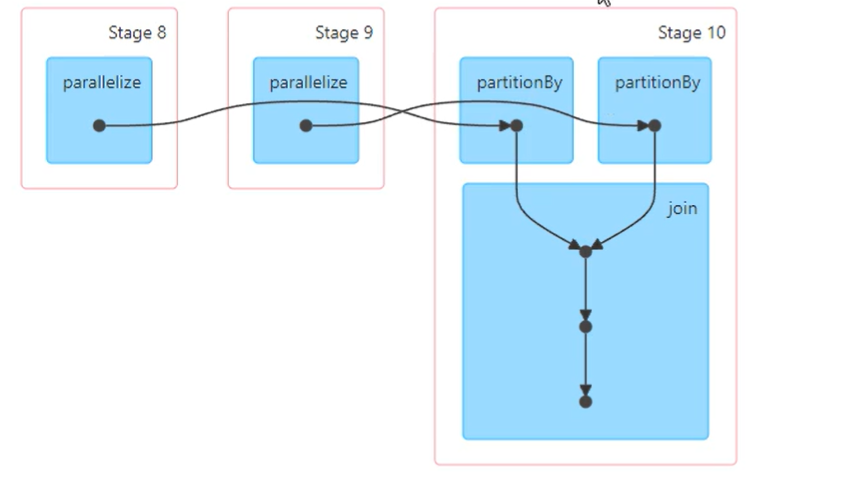
问:如果rdd1.join(rdd2) ,join算子不传入分区器会有shuffle吗?
不会shuffle,因为会沿用父节点的最大分区器。最终结果还是默认产生了一个Hashpartitioner(2)
总结
如果父RDD最大分区器的并行度能够承载其它父RDD的并行度(10倍以内),那就沿用父RDD的最大分区器
如果父RDD没有最大分区器或者承载不了那就new HashPartitioner(defaultParalleize)
通常父RDD只有一个,那就没这么麻烦,父RDD有分区器的直接沿用父RDD的分区器,没有就
new HashPartitioner(defaultParalleize)
但是!!!!!!!!!!
有的看似父RDD有分区器,依然没有被沿用,请注意算子内部的RDD转换导致分区器被隐形擦除了