
一口一口吃掉yolov8(2)
创始人
2025-05-31 10:02:43
前面介绍了训练的第一个部分,也是大部分人在网上找得到的文章,但是后面2个部分应该是网上没有的资料了,希望大家喜欢。
0.数据
我的数据是一些栈板,主要是检测栈板的空洞,识别出空洞的位置和偏转角度。原图如下

我的标注

我用labelme标注,然后转为yolo格式,转换代码如下。
# coding=utf-8
import os
import syspath = os.path.dirname(__file__)
sys.path.append(path)'''
Author:Don
date:2022/8/3 11:49
desc:
'''
import os
import json
import glob
#输入口,就是你图片和json存放的那个文件,输出的txt也在这个文件夹里
labelme_dir=r"E:\2022\work\shchaiduo\image"def get_labelme_data(labelme_dir):with open(labelme_dir) as f:j=json.load(f)out_data=[]img_h =j["imageHeight"]img_w =j["imageWidth"]for shape in j["shapes"]:label=shape["label"]points=shape["points"]x,y,x2,y2=points[0][0],points[0][1],points[1][0],points[1][1]x_c=(x+x2)//2y_c=(y+y2)//2w=abs(x-x2)h=abs(y-y2)out_data.append([label,x_c,y_c,w,h])return img_h,img_w,out_datadef rename_Suffix(in_,mode=".txt"):in_=in_.split('.')return in_[0]+modedef make_yolo_data(in_dir):json_list=glob.glob(os.path.join(in_dir,'*.json'))for json_ in json_list:json_path=os.path.join(in_dir,json_)json_txt=rename_Suffix(json_)img_h,img_w,labelme_datas=get_labelme_data(json_path)with open(os.path.join(in_dir,json_txt),'w+') as f:for labelme_data in labelme_datas:label=labelme_data[0]x_c=labelme_data[1]/img_wy_c=labelme_data[2]/img_hw=labelme_data[3]/img_wh=labelme_data[4]/img_hf.write("{} {} {} {} {}\n".format(label,x_c,y_c,w,h))f.close()if __name__ == '__main__':make_yolo_data(labelme_dir)
images是图片
labels是标签 txt格式
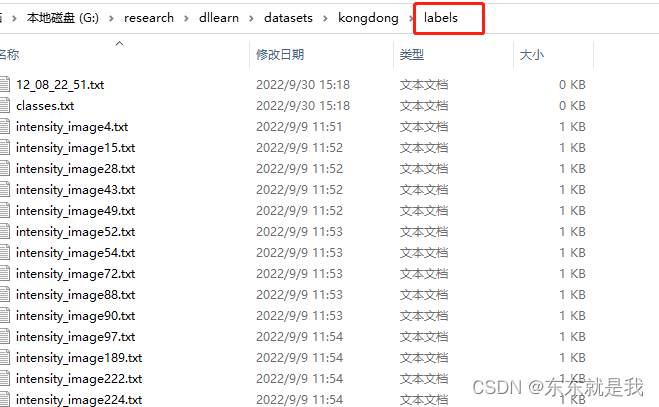
具体的是下图, 0是标签标识,因为只有一个class 所以我的数据里第一个都是0,后面是对应孔洞的xywh,但是要除以图片的长宽,具体的看上面的标签转换代码。 因为一个托盘只有2个孔洞,所以我的一个txt 只有2组数据。

test是图片
1.训练前数据准备
因为我的数据是实际现场采集的,所以很多数据增强的技术并不需要(个人理解)。在工业上,最重要的是安全而不是精度。意思就是如果是正确的就是100%,如果是错误的就是0%,最好不存在误检,漏检是可以接受的。所以模型不建议有更好的泛化能力。最好是没见过的东西就直接报警处理,而不是给出大概的检测范围。所以我只用了v8中的aLbumentations api 其他的都去掉了。默认batch_size=1。

from pathlib import Path
import glob
import os
from torch.utils.data import Dataset
from tqdm import tqdm
from multiprocessing.pool import ThreadPool
from PIL import Image, ImageOps
import random
import albumentations as A
import numpy as np
import torchNUM_THREADS = min(8, max(1, os.cpu_count() - 1)) # number of YOLOv5 multiprocessing threads
TQDM_BAR_FORMAT = '{l_bar}{bar:10}{r_bar}' # tqdm bar format
IMG_FORMATS = "bmp", "dng", "jpeg", "jpg", "mpo", "png", "tif", "tiff", "webp", "pfm" # include image suffixesclass Albumentations:# YOLOv8 Albumentations class (optional, only used if package is installed)def __init__(self, p=1.0):self.p = pT = [A.Blur(p=0.01),A.MedianBlur(p=0.01),A.ToGray(p=0.01),A.CLAHE(p=0.01),A.RandomBrightnessContrast(p=0.0),A.RandomGamma(p=0.0),A.ImageCompression(quality_lower=75, p=0.0), ] # transformsself.transform = A.Compose(T, bbox_params=A.BboxParams(format="yolo", label_fields=["class_labels"]))def __call__(self, labels):im = labels["img"]cls = labels["cls"]if len(cls):if self.transform and random.random() < self.p:new = self.transform(image=im, bboxes=labels["bboxes"], class_labels=cls) # transformedlabels["img"] = self._format_img(new["image"])labels["cls"] = torch.tensor(new["class_labels"])labels["bboxes"] = torch.tensor(new["bboxes"])labels["batch_idx"] = torch.zeros(labels["cls"].shape[0])return labelsdef _format_img(self, img):if len(img.shape) < 3:img = np.expand_dims(img, -1)img = np.ascontiguousarray(img.transpose(2, 0, 1)[::-1]).astype(np.float32)img = torch.from_numpy(img)return img# 读取数据集存储
def verify_image_label(args):im_file, lb_file = argstry:im = Image.open(im_file)im.verify() # PIL verifyshape = im.size # image sizeshape = (shape[1], shape[0]) # hwif im.format.lower() in ("jpg", "jpeg"):with open(im_file, "rb") as f:f.seek(-2, 2)if f.read() != b"\xff\xd9": # corrupt JPEGImageOps.exif_transpose(Image.open(im_file)).save(im_file, "JPEG", subsampling=0, quality=100)# verify labelsif os.path.isfile(lb_file):with open(lb_file) as f:lb = [x.split() for x in f.read().strip().splitlines() if len(x)]lb = np.array(lb, dtype=np.float32)nl = len(lb)if nl:_, i = np.unique(lb, axis=0, return_index=True)if len(i) < nl: # duplicate row checklb = lb[i] # remove duplicateselse:lb = np.zeros((0, 5), dtype=np.float32)else:lb = np.zeros((0, 5), dtype=np.float32)lb = lb[:, :5]return im_file, lb, shapeexcept Exception as e:return [None, None, None]class YOLODataset(Dataset):def __init__(self, img_path, imgsz=640, augment=True):super(YOLODataset, self).__init__()self.img_path = img_pathself.imgsz = imgszself.augment = augmentself.im_files = self.get_img_files(self.img_path) # 读取图片self.labels = self.get_labels() # 读取labelself.ni = len(self.labels)# transformsself.transforms = Albumentations(p=1.0)def get_img_files(self, img_path):"""Read image files."""try:f = [] # image filesfor p in img_path if isinstance(img_path, list) else [img_path]:p = Path(p) # os-agnosticif p.is_dir(): # dirf += glob.glob(str(p / "**" / "*.*"), recursive=True)elif p.is_file(): # filewith open(p) as t:t = t.read().strip().splitlines()parent = str(p.parent) + os.sepf += [x.replace("./", parent) if x.startswith("./") else x for x in t] # local to global pathim_files = sorted(x.replace("/", os.sep) for x in f if x.split(".")[-1].lower() in IMG_FORMATS)except Exception as e:raise FileNotFoundError(f"Error loading data from") from ereturn im_filesdef img2label_paths(self, img_paths):# Define label paths as a function of image pathssa, sb = f"{os.sep}images{os.sep}", f"{os.sep}labels{os.sep}" # /images/, /labels/ substringsreturn [sb.join(x.rsplit(sa, 1)).rsplit(".", 1)[0] + ".txt" for x in img_paths]def get_labels(self):self.label_files = self.img2label_paths(self.im_files)cache_path = Path(self.label_files[0]).parent.with_suffix(".cache")try:cache, exists = np.load(str(cache_path), allow_pickle=True).item(), True # load dictexcept (FileNotFoundError, AssertionError, AttributeError):cache, exists = self.cache_labels(cache_path), False # run cache opsreturn cache["labels"]def cache_labels(self, path=Path("./labels.cache")):# Cache dataset labels, check images and read shapesif path.exists():path.unlink() # remove *.cache file if existsx = {"labels": []}desc = f"Scanning {path.parent / path.stem}..."total = len(self.im_files)with ThreadPool(NUM_THREADS) as pool:results = pool.imap(func=verify_image_label,iterable=zip(self.im_files, self.label_files)) # im_file, lb, shapepbar = tqdm(results, desc=desc, total=total, bar_format=TQDM_BAR_FORMAT)for im_file, lb, shape, in pbar:if im_file:x["labels"].append(dict(im_file=im_file,shape=shape,cls=lb[:, 0:1], # n, 1bboxes=lb[:, 1:], # n, 4segments=None,keypoints=None,normalized=True,bbox_format="xywh"))pbar.close()np.save(str(path), x) # save cache for next timereturn x
2. 训练中取数据
取数据,要实现len 和getitem函数 ,因为使用的是torch的dataset。因为我们要重写index ,所以重写了collate_fn函数

def __len__(self):return len(self.labels)def __getitem__(self, index):return self.transforms(self.get_label_info(index))def get_label_info(self, index):label = self.labels[index].copy()label["img"], label["ori_shape"], label["resized_shape"] = self.load_image(index)return labeldef load_image(self, i):# Loads 1 image from dataset index 'i', returns (im, resized hw)f = self.im_files[i]im = cv2.imread(f) # BGRif im is None:raise FileNotFoundError(f"Image Not Found {f}")h0, w0 = im.shape[:2] # orig hwr = self.imgsz / max(h0, w0) # ratioif r != 1: # if sizes are not equalinterp = cv2.INTER_LINEAR if (self.augment or r > 1) else cv2.INTER_AREAim = cv2.resize(im, (640, 512), interpolation=interp)return im, (h0, w0), im.shape[:2] # im, hw_original, hw_resized@staticmethoddef collate_fn(batch):new_batch = {}keys = batch[0].keys()values = list(zip(*[list(b.values()) for b in batch]))for i, k in enumerate(keys):value = values[i]if k == "img":value = torch.stack(value, 0)if k in ["bboxes", "cls"]:value = torch.cat(value, 0)new_batch[k] = valuenew_batch["batch_idx"] = list(new_batch["batch_idx"])for i in range(len(new_batch["batch_idx"])):new_batch["batch_idx"][i] += i # add target image index for build_targets()new_batch["batch_idx"] = torch.cat(new_batch["batch_idx"], 0)return new_batch
3.整合数据
def seed_worker(worker_id):# Set dataloader worker seed https://pytorch.org/docs/stable/notes/randomness.html#dataloaderworker_seed = torch.initial_seed() % 2 ** 32np.random.seed(worker_seed)random.seed(worker_seed)TQDM_BAR_FORMAT = '{l_bar}{bar:10}{r_bar}' # tqdm bar format
img_path = "../datasets/kongdong/images"
dataset = YOLODataset(img_path=img_path, imgsz=640, augment=True)
RANK = int(os.getenv('RANK', -1))
PIN_MEMORY = str(os.getenv("PIN_MEMORY", True)).lower() == "true"
generator = torch.Generator()
generator.manual_seed(6148914691236517205 + RANK)
train_loader = DataLoader(dataset=dataset, batch_size=1, shuffle=True,pin_memory=PIN_MEMORY,collate_fn=getattr(dataset, "collate_fn", None),worker_init_fn=seed_worker,generator=generator)
pbar = tqdm(enumerate(train_loader), total=1, bar_format=TQDM_BAR_FORMAT)
for i, batch in pbar:
我们for 循环取数据集 那么batch里面有什么呢。我们看一下
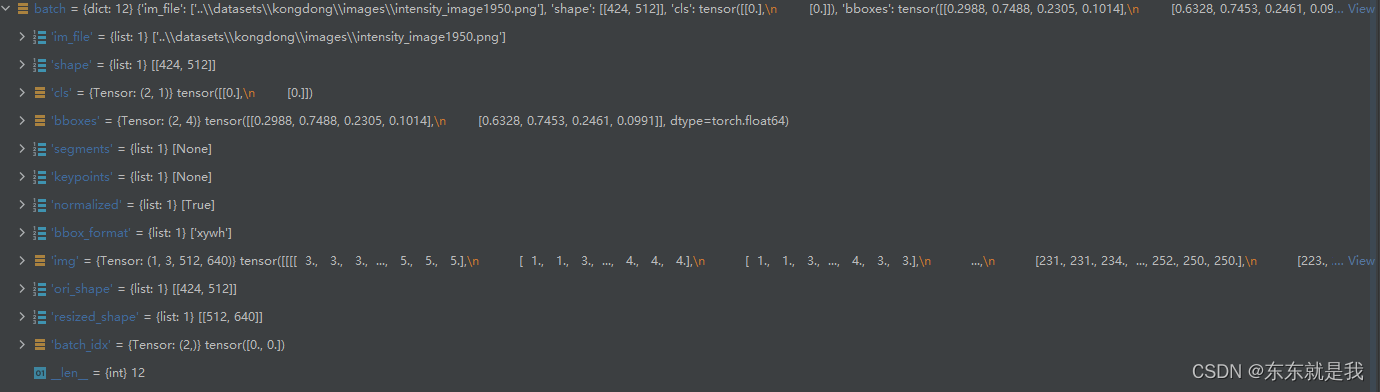
现在我们检测一下数据做了变换后是否正确
# 检测输入的数据图像对不对
def check_data(batch):img = batch["img"]labels = batch['bboxes'] # xywhlabels[:, 0] *= 640labels[:, 1] *= 512labels[:, 2] *= 640labels[:, 3] *= 512input_tensor = img.squeeze()# 从[0,1]转化为[0,255],再从CHW转为HWC,最后转为cv2input_tensor = input_tensor.permute(1, 2, 0).type(torch.uint8).numpy()# RGB转BRGinput_tensor = cv2.cvtColor(input_tensor, cv2.COLOR_RGB2BGR)for box in labels.int(): # xywhcv2.rectangle(input_tensor, (int(box[0] - box[2] / 2), int(box[1] - box[3] / 2)),(int(box[0] + box[2] / 2), int(box[1] + box[3] / 2)), (255, 0, 255), -1)cv2.imshow('img', input_tensor)cv2.waitKey(0)for i, batch in pbar:# Forwardwith torch.cuda.amp.autocast(False):check_data(batch)img = batch["img"]preds = model(img)
ok,正确的,
我们再看一下模型的输出是否正确
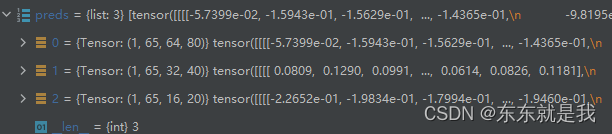
ok,和我们第一个文章上前向推理网络的输出大小一致。
相关内容
热门资讯
国内充电基础设施发展缓慢的真正...
今天给各位分享国内充电基础设施发展缓慢的真正原因是什么?cbyl的怂货的知识,其中也会对充电基础设施...
回首掏走位走位什么梗,“回首掏...
回首掏走位走位什么梗目录回手掏什么意思“回首掏”是什么意思?回手掏是什么梗 回手掏什么意思“回手掏,...
带龙凤的成语有啥,龙凤的成语有...
带龙凤的成语有啥目录带龙凤的成语有啥龙凤的成语有哪些有关龙凤的成语和龙凤有关的成语带龙凤的成语有啥 ...
C++演讲比赛流程管理系统_黑...
任务 学校演讲比赛,12人,两轮,第一轮淘汰赛...
复联4有彩蛋吗,《复联4》古一...
复联4有彩蛋吗目录复联4有彩蛋吗《复联4》古一怎么知道五年后的事,为何会把时间宝石交给班纳?《复联4...
labview数据类型转换字符...
wx供重浩:创享日记 对话框发送:labview转换 获取完整无水印报告...
【分享】国内如何使用chatG...
上周,OpenAI宣布正式发布多模态预训练大模型GPT-4,其强大的能力...
软件智能:aaas系统中AI的...
概要(内容概述) <同一>将设计目标确定为“软件智能”的aaas中,AI的任务和AI能...
早日康复祝福语简短8字,早日康...
早日康复祝福语简短8字目录早日康复祝福语简短8字早日康复祝福语简短8字搞定手术祝福语8个字早日康复祝...
淘宝店铺名怎么改,淘宝店铺怎么...
淘宝店铺名怎么改目录淘宝店铺名怎么改淘宝店铺怎么改名淘宝店铺名可以修改吗,怎样修改怎么修改淘宝店铺名...
微信助手怎么查单删 极速百科网...
微信助手怎么查单删目录微信助手怎么查单删微信助手怎么查单删微信如何查单删 2016微信如何知道对方有...
陆家嘴都有什么旅游景点 极速百...
陆家嘴都有什么旅游景点目录陆家嘴都有什么旅游景点陆家嘴都有什么旅游景点陆家嘴有哪些旅游景点上海陆家嘴...
1229 - 拦截导弹的系统数...
1229 - 拦截导弹的系统数量求解 题目描述 某国为了防御敌国的导弹袭击,发展出一种...
如何做好项目缺陷管理
缺陷管理是项目管理工作中的重要环节。Excel表格是国内团队常用的缺陷管理工具,具备上...
Python生成器
1.生成器 生成器是一种特殊的迭代器,它是通过函数来实现的。生成器函数每次执行到yi...
Nginx可视化管理工具 - ...
一、介绍 nginx-proxy-manager 是一个反向代理管理系统,它基于Nginx,具有漂亮...
如何解除迅雷安全模式,迅雷怎样...
如何解除迅雷安全模式目录如何解除迅雷安全模式迅雷怎样解除安全模式迅雷VIP尊享版怎么解除安全模式?迅...
感谢朋友圈留言句子,适合发朋友...
感谢朋友圈留言句子目录感谢朋友圈留言句子适合发朋友圈表达感谢的句子20句发朋友圈的感谢短语有哪些?有...
关于韩娱的小说有没有什么好看的...
关于韩娱的小说有没有什么好看的目录关于韩娱的小说有没有什么好看的求好看的韩娱小说有没有好看的韩娱小说...
什么是表面粗糙度(什么是表面粗...
本篇文章极速百科给大家谈谈什么是表面粗糙度,以及什么是表面粗糙度?它对零件的使用性能有什么影响?对应...
永远用英语怎么说,“永远”除了...
永远用英语怎么说目录永远用英语怎么说“永远”除了“forever”的英文翻译~~还有哪些
少年音怎么练,怎么配出清爽的少...
少年音怎么练目录少年音怎么练怎么配出清爽的少年音?怎么学正太音少年音,像是龙马啊、镜音连啊不二啊那种...
情侣之间的爱称有哪些,情侣称呼...
情侣之间的爱称有哪些目录情侣之间的爱称有哪些情侣称呼有创意的爱称情侣之间好听的称呼都有什么?情侣爱称...
共享汽车怎么租车 极速百科网 ...
共享汽车怎么租车目录共享汽车怎么租车共享汽车怎么租车gofun出行有人开吗?使用方法是什么?共享汽车...
Python应用之爬虫基础:r...
引言 在生活中,大家都使用过浏览器,通过输入要搜索的内容以及鼠标点击等操...
jsp医疗辅助诊断管理系统se...
一、源码特点 JSP医疗辅助诊断管理系统是一套完善的java web信息管理系统ÿ...
db19密钥库和加密
创建密钥库ENCRYPTION_WALLET_LOCATION =(SOURCE =...
开局之年是什么意思(开局之年之...
本篇文章极速百科给大家谈谈开局之年是什么意思,以及开局之年之后是什么年对应的知识点,希望对各位有所帮...
抖音gga什么意思(抖音gg是...
本篇文章极速百科给大家谈谈抖音gga什么意思,以及抖音gg是什么意思对应的知识点,希望对各位有所帮助...
DMZ是什么(防火墙的dmz是...
今天给各位分享DMZ是什么的知识,其中也会对防火墙的dmz是什么进行解释,如果能碰巧解决你现在面临的...