
Python应用之爬虫基础:requests爬虫库的简单使用(1)
引言
在生活中,大家都使用过浏览器,通过输入要搜索的内容以及鼠标点击等操作方式,来获取互联网上的信息。直观的理解这个过程就是,客户端(用户)发送请求给服务器,服务器通过解析请求,将用户需要的信息作为响应内容传回去。
什么是爬虫
那这跟爬虫有啥关系?爬虫这种类型的程序,能够模拟人的操作来自动获取相关的信息,由于人获取信息会受到操作速度上的限制,使用爬虫可以在短时间内获取到大量信息
一个爬虫程序的产生,可以分为一下几个步骤
- 获取要访问的内容的链接url
- 设置爬虫的请求头部等字段信息(可选步骤)
- 发送某种类型的请求
- 获取得到响应,对响应内容进行分析提取需要的内容
其中1、2步骤的顺序不是绝对的,url、字段信息等内容,绝大部分情况下都需要动态生成,这部分将在后续的文章中进行讲解。
接下来将通过一个简单的案例来创建爬虫程序。
准备工作
requests库的安装
pip install requests
代码部分
简单爬虫
import requestsdef GetResponse1():url = "https://www.baidu.com"# 这个get代表使用get方法请求该url# 返回值是 服务器给get请求的响应封装成的Response对象response = requests.get(url=url)# response.content是二进制的响应数据print(response.request.headers)print(response.content.decode())print(len(response.text))if __name__ == "__main__":GetResponse1()
这是一个最简单的爬虫程序,未设置任何字段,运行结果如下:

但响应的长度只有2443,似乎有点短,这里的问题出在请求头的User-Agent的未设置,默认是python-requests/2.28.2,导致百度发现这是一个爬虫而不是浏览器,因此返回给我们的并非是一个正确的界面,通过设置这个字段来解决这个问题。
代码如下:
import requestsdef GetResponse1():url = "https://www.baidu.com"headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.5359.95 Safari/537.36 QIHU 360SE'}response = requests.get(url=url,headers=headers)# print(response.request.headers)# print(response.content.decode())print(len(response.text))if __name__ == "__main__":GetResponse1()
这样就能获取正确的页面了
注意:User-Agent的百度找一下,也可以查看自己浏览器的User-Agent
查看自己浏览器的User-Agent
步骤如下:
打开自己的浏览器---------->>按F12打开开发者工具---------->>点击网络功能,选中全部按钮---------->>按F5刷新一下进行抓包---------->>抓到的东西,随便选一个,就能看到User-Agent了
结果图如下
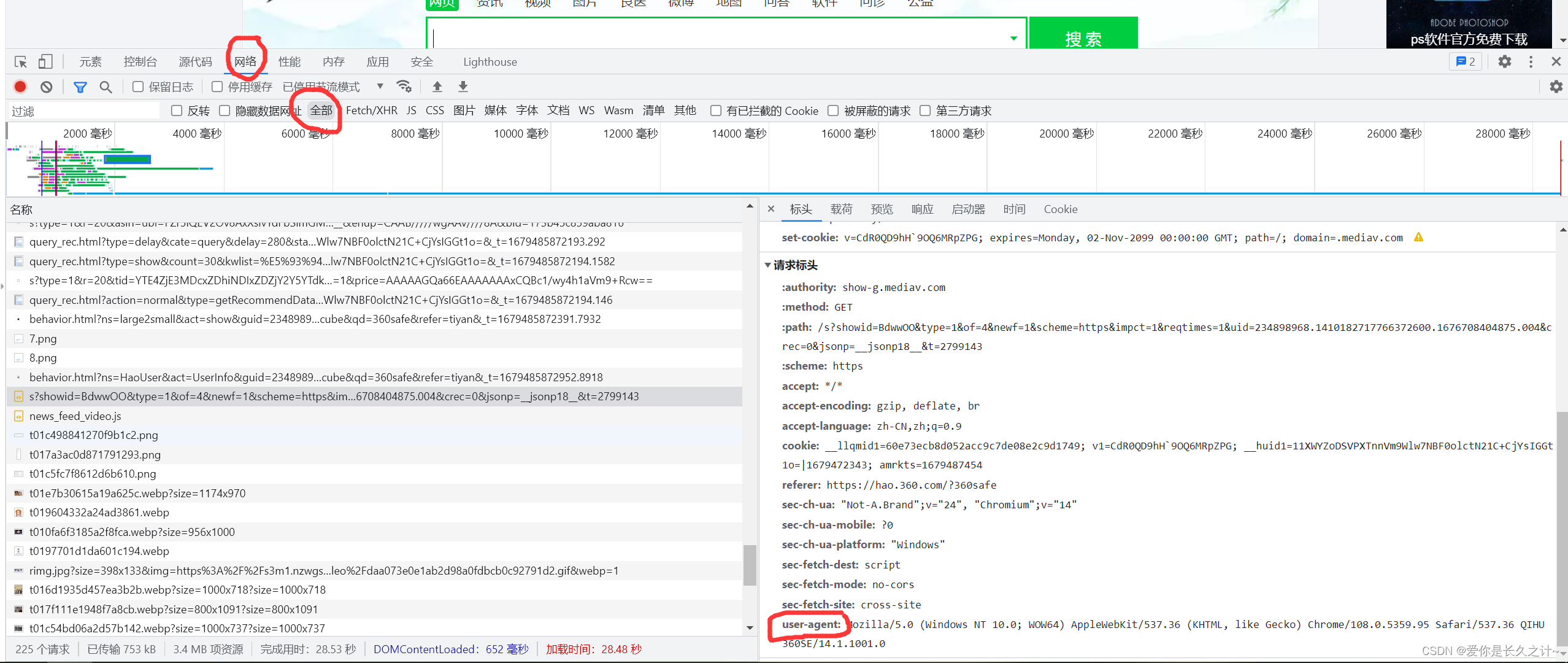
浏览器自带的开发者工具功能很强大,大部分爬虫的开发都会使用它来抓包分析。
Response对象解析
# Response对象的常用属性与方法
def attrs():url = "https://www.baidu.com"response = requests.get(url=url)# 响应的真实地址 也就是最终跳转的并返回给你的urlprint(response.url)# 状态码print(response.status_code)# 请求头print(response.request.headers)# 响应头print(response.headers)# 响应中携带的cookiesprint(response.cookies)# content是二进制的响应数据 这里decode能解决中文乱码问题print(response.content.decode(encoding='utf8'))
在获取响应的数据时,推荐使用response.content.decode()而不是response.text,可以同设置编码字符集来解决中文乱码的问题
模拟浏览器来查询
在百度界面,输入python进行搜索,能得到以下界面:

在地址栏里,可以得到一个链接:
https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=1&tn=baidu&wd=python&fenlei=256&rsv_pq=0xd9be4c3000077eb1&rsv_t=0bb0WRpffKNGHcOpAMRtHYKVb4%2Ftb4jsrpl8LBciDmX7wYA0osUpZvWRaNwa&rqlang=en&rsv_enter=1&rsv_dl=tb&rsv_sug3=7&rsv_sug1=6&rsv_sug7=100&rsv_sug2=0&rsv_btype=i&prefixsug=python&rsp=5&inputT=1544&rsv_sug4=2289
这是带了参数的链接,里面必定有关键参数(也就是不可缺少的,如查询字符串),也有一些参数是可有可无的,因此要使用爬虫模拟请求,也就需要找到关键参数,如何找:通过反复删除参数同时访问该链接,直到页面不能正常显示为止,那么上一次删除的参数里面就有关键参数。
通过测试,关键参数的key为wd,等号=后面的就是查询的值。
下面利用爬虫模拟浏览器搜索
# 带参数的请求
def sendPara1():# 加上user-agent就能初步蒙混过关# https://www.baidu.com/s?wd=python# 通过parameter属性 来设置关键参数headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.5359.95 Safari/537.36 QIHU 360SE'}url = "https://www.baidu.com/s?"kw = {'wd': 'python'}# 通过params设置参数response = requests.get(url=url, headers=headers, params=kw)# 关键参数 可以通过查询的时候 删除参数来确定with open('python.html', 'wb') as f:f.write(response.content)
打开得到了 python.html,可以得到如下的界面就代表成功