
【BBuf的CUDA笔记】九,使用newbing(chatgpt)解析oneflow softmax相关的fuse优化
0x0. 背景
随着年纪越来越大,读代码越来越困难,如果你发现看不懂同事写的代码应该怎么办呢?不要担心,大语言模型的时代了来了,chatgpt和gpt4会教会我们怎么读代码。本篇文章就来展示一下使用newbing(chatgpt)来读oneflow softmax相关的fuse优化kernel的过程。本文的代码解释均由chatgpt生成,我只是手工做了非常少的一点微调来保证对代码解释的正确性。完整代码解释见: https://github.com/BBuf/how-to-optim-algorithm-in-cuda/blob/master/oneflow-cuda-optimize-skills/fused_softmax/fused_scale_mask_softmax.cu#L1452-L2098
我在【BBuf的CUDA笔记】八,对比学习OneFlow 和 FasterTransformer 的 Softmax Cuda实现 中对oneflow以及FasterTransformer做了源码解析,读者可以先了解一下。在oneflow的softmax cuda kernel中已经提到它的每种实现均有LOAD、STORE两个模板参数分别代表输入输出。使用 load.template load 和store.template store 进行读取和写入。使用LOAD和STORE有两个好处:1、可以在CUDA Kernel中只关心计算类型ComputeType,而不用关心具体的数据类型T。2、只需要加几行代码就可以快速支持Softmax和其他Kernel Fuse,减少带宽需求,提升整体性能。普通的SoftmaxKernel直接使用DirectLoad和DirectStore,FusedScaleSoftmaxKernel(也就是本文要介绍的)只需要额外定义一个ScaleMaskLoad结构用于对输入x做Scale预处理以及ScaleMaskStore即可快速完成kernel fuse。
本篇文章在oneflow softmax的基础上将fused_scale_mask_softmax的完整实现抽取到了https://github.com/BBuf/how-to-optim-algorithm-in-cuda/blob/master/oneflow-cuda-optimize-skills/fused_softmax/fused_scale_mask_softmax.cu 文件中并进行解析,读者可以使用 https://github.com/BBuf/how-to-optim-algorithm-in-cuda/blob/master/oneflow-cuda-optimize-skills/fused_softmax/Makefile 文件来编译这个.cu文件并运行,得到正确的结果。
0x1. Pattern介绍
我们先来介绍一下我们要做的这个fuse pattern是什么样子的,其实它就是Transformer解码模块的softmax部分,由于解码时无法看到当前token的后续token,所以需要对输入做一个mask scale操作。具体来说就是把mask tensor中为true的位置对应的原始tensor元素乘以一个常数scale,并且把mask tensor中为false的位置对应的原始tensor元素填充为一个-inf。其实也不一定是inf,只要足够大就可以了,比如经常取10000.0。用python代码表达这个pattern就是这样子的:
import numpy as np
import oneflow as flowbatch_size = 4
num_heads = 8
seq_length = 64
broadcast_dim = 1
fill_value = -10000.0
scale_value = 2.0x = np.random.randn(batch_size, num_heads, seq_length, seq_length).astype(np.float32
)
mask_size = [batch_size, num_heads, seq_length, seq_length]
if broadcast_dim:mask_size[broadcast_dim] = 1mask = np.random.randint(0, 2, size=mask_size, dtype=bool)
fused_x_tensor = flow.tensor(x, dtype=flow.float32).to("cuda")
fused_mask_tensor = flow.tensor(mask, dtype=flow.bool).to("cuda")
fused_x_tensor.requires_grad = Truefused_out = flow._C.fused_scale_mask_softmax(fused_x_tensor, fused_mask_tensor, fill_value=fill_value, scale=scale_value,
)origin_x_tensor = flow.tensor(x).to("cuda")
origin_mask_tensor = flow.tensor(mask, dtype=flow.float32).to("cuda")
origin_out = flow.mul(origin_x_tensor, origin_mask_tensor
) * scale_value + fill_value * (1.0 - origin_mask_tensor)
origin_out = flow.softmax(origin_out, dim=-1)
assert(np.allclose(fused_out.numpy(), origin_out.numpy(), atol=1e-4, rtol=1e-4))
这个pattern就是把flow.mul(origin_x_tensor, origin_mask_tensor) * scale_value + fill_value * (1.0 - origin_mask_tensor)里面的操作融合为一个cuda kernel,也就是flow._C.fused_scale_mask_softmax(fused_x_tensor, fused_mask_tensor, fill_value=fill_value, scale=scale_value,) 。额外需要注意的是这个mask是支持广播的,所以oneflow中对softmax kernel中的LOAD和STORE分别定义了BroadcastScaleMaskLoad/ElementwiseScaleMaskLoad以及BroadcastScaleMaskStore/ElementwiseScaleMaskStore 2组实现来进行fused_scale_mask_softmax算子的数据读取和存储。
0x2. 使用chatgpt来读代码实现
接下来我们就用chatgpt来读一读BroadcastScaleMaskLoad/ElementwiseScaleMaskLoad以及BroadcastScaleMaskStore/ElementwiseScaleMaskStore的实现。
首先来看ElementwiseScaleMaskLoad的实现:
template
struct ElementwiseScaleMaskLoad {ElementwiseScaleMaskLoad(const SRC* src, const MASK* mask, ElementwiseMaskSoftmaxParams param): src(src), mask(mask), param(param) {}template__device__ void load(DST* dst, int64_t row, int64_t col) {Pack pack;const int64_t offset = (row * param.row_size + col) / N;pack.storage = *(reinterpret_cast*>(src) + offset);Pack mask_pack;mask_pack.storage = *(reinterpret_cast*>(mask) + offset);
#pragma unrollfor (int i = 0; i < N; ++i) {if (mask_pack.elem[i] == 0) {dst[i] = static_cast(param.fill);} else {dst[i] = static_cast(pack.elem[i]) * static_cast(param.scale);}}}const SRC* src;const MASK* mask;ElementwiseMaskSoftmaxParams param;
};
我们让chatgpt来帮我们分析一下这个结构体,chatgpt为我们分析了这个结构体并给出了以下的信息:
// 它的功能是定义一个模板类,用于在kernel函数中加载逐元素掩码softmax的输入。它的模板参数有:
// SRC: 源张量的数据类型
// DST: 目标张量的数据类型
// MASK: 掩码张量的数据类型
// 它的构造函数接受以下参数:
// src: 源张量的指针
// mask: 掩码张量的指针
// param: 逐元素掩码softmax的参数,是一个ElementwiseMaskSoftmaxParams结构体的实例
// load: 一个模板函数,用于从源张量和掩码张量中加载N个元素,并将它们存储到目标张量中。它接受以下参数:
// dst: 目标张量的指针
// row: 当前的行号
// col: 当前的列号
// 它的内部逻辑是:
// 根据行号和列号计算源张量和掩码张量的偏移量
// 从源张量和掩码张量中读取N个元素,分别存储到pack和mask_pack中
// 遍历N个元素,如果掩码张量的元素为0,就将目标张量的元素设为填充值,否则就将源张量的元素乘以缩放因子,并转换为目标张量的数据类型
// 这个模板类的成员变量有:
// src: 源张量的指针
// mask: 掩码张量的指针
// param: 逐元素掩码softmax的参数,是一个ElementwiseMaskSoftmaxParams结构体的实例
// 这个模板类的目的是为了方便在kernel函数中使用逐元素掩码softmax的输入,提高深度学习的性能。
可以看到chatgpt给出了非常详细的逻辑解释,并且还指出提高深度学习性能。提高深度学习性能这句话应该是猜出来的,毕竟从这段代码chatgpt是不可能了解到这个结构体是和softmax fuse kernel相关的,但能感觉到chatgpt是真的有理解这段代码已经非常厉害了。接着我们问问#pragma unroll这一行代码是干什么的?
 我们再问一下这里的Pack是什么意思?
我们再问一下这里的Pack是什么意思?
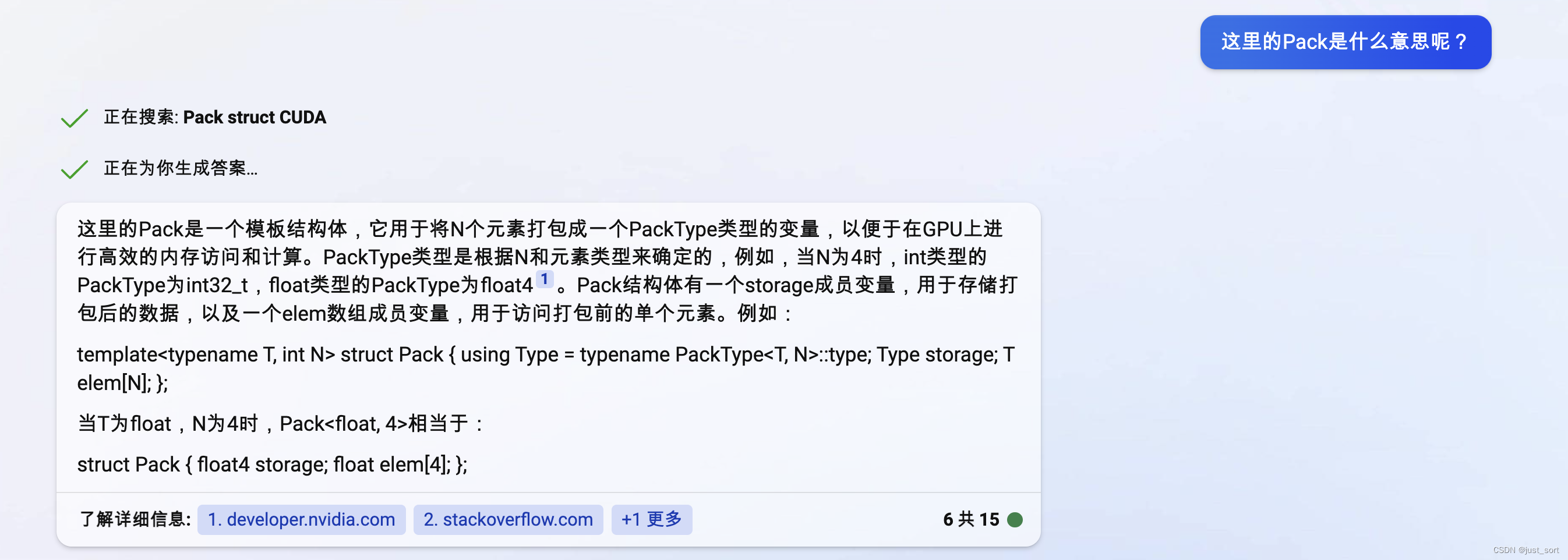
可以看到chatgpt还是较为准备的为我们解释了这里Pack的含义以及指出是便于在GPU上进行高效的内存访问。
最后再拷打一下pack.storage = *(reinterpret_cast这句话涉及到的逻辑:

太强了,根本难不倒他。当然了,一般element_wise相关的定义都是略显简单的,如果我们加入广播的逻辑也就是让chatgpt来读一下BroadcastScaleMaskLoad看看效果如何:
// 它的功能是定义一个模板类,用于在内核函数中加载广播掩码softmax的输入。它的模板参数有:
// SRC: 源张量的数据类型
// DST: 目标张量的数据类型
// MASK: 掩码张量的数据类型
// num_dims: 张量的维度数
// IndexType: 索引的数据类型
// 它的构造函数接受以下参数:
// src: 源张量的指针
// mask: 掩码张量的指针
// params: 广播掩码softmax的参数,是一个BroadcastMaskSoftmaxParams结构体的实例
// 它的成员函数有:
// load: 一个模板函数,用于从源张量和掩码张量中加载N个元素,并将它们存储到目标张量中。它接受以下参数:
// dst: 目标张量的指针
// row: 当前的行号
// col: 当前的列号
// 它的内部逻辑是:
// 根据行号和列号计算源张量的偏移量
// 根据偏移量计算源张量的多维索引
// 根据多维索引计算掩码张量的偏移量
// 从源张量和掩码张量中读取N个元素,分别存储到pack和mask_pack中
// 遍历N个元素,如果掩码张量的元素为0,就将目标张量的元素设为填充值,否则就将源张量的元素乘以缩放因子,并转换为目标张量的数据类型
// 这个模板类的成员变量有:
// src: 源张量的指针
// mask: 掩码张量的指针
// mask_dims: 掩码张量的每个维度的大小,是一个数组
// params: 广播掩码softmax的参数,是一个BroadcastMaskSoftmaxParams结构体的实例
// 这个模板类的目的是为了方便在内核函数中使用广播掩码softmax的输入,提高深度学习的性能。
template
struct BroadcastScaleMaskLoad {BroadcastScaleMaskLoad(const SRC* src, const MASK* mask,BroadcastMaskSoftmaxParams params): src(src), mask(mask), params(params) {for (int i = 0; i < num_dims; i++) { mask_dims[i] = params.mask_dims[i]; }}template__device__ void load(DST* dst, int64_t row, int64_t col) {Pack pack;Pack mask_pack;const IndexType offset = row * params.row_size + col;IndexType input_index[num_dims];IndexType mask_index[num_dims];params.src_index_helper.OffsetToNdIndex(offset, input_index);for (int dim = 0; dim < num_dims; ++dim) {if (mask_dims[dim] == 1) {mask_index[dim] = 0;} else {mask_index[dim] = input_index[dim];}}const IndexType mask_offset = params.mask_index_helper.NdIndexToOffset(mask_index);pack.storage = *(reinterpret_cast*>(src) + offset / N);mask_pack.storage =*(reinterpret_cast*>(mask) + mask_offset / N);
#pragma unrollfor (int i = 0; i < N; ++i) {if (mask_pack.elem[i] == 0) {dst[i] = static_cast(params.fill);} else {dst[i] = static_cast(pack.elem[i]) * static_cast(params.scale);}}}const SRC* src;const MASK* mask;int64_t mask_dims[num_dims];BroadcastMaskSoftmaxParams params;
};
chatgpt给了我们一份看起来非常合理的注释,并且似乎它已经参透了这个结构体类就是为了方便在kernel函数中使用广播掩码softmax的输入。接下来我们依旧拷打一下细节,首先我们来问一下BroadcastMaskSoftmaxParams这个结构体类,并让它给出解释:
// 它的功能是定义一个结构体,用于存储广播掩码softmax的参数。
// 广播掩码softmax是一种在不同形状的张量之间进行softmax运算的方法,
// 它会将较小的张量扩展到较大的张量的形状上,并用一个掩码张量来指定哪些位置需要计算softmax,
// 哪些位置需要填充一个固定的值。这个结构体的成员变量有:
// src_index_helper: 一个用于计算源张量索引的辅助类
// mask_index_helper: 一个用于计算掩码张量索引的辅助类
// mask_dims: 掩码张量的每个维度的大小
// row_size: 每一行的元素个数
// fill: 填充的值
// scale: softmax的缩放因子
// 这个结构体的目的是为了方便在内核函数中使用广播掩码softmax的参数,提高深度学习的性能。
template
struct BroadcastMaskSoftmaxParams {NdIndexOffsetHelper src_index_helper;NdIndexOffsetHelper mask_index_helper;const int64_t* mask_dims{};int64_t row_size;float fill;float scale;
};
非常准确!接着我们再问一下NdIndexOffsetHelper这个类的细节,chatgpt给出的回答如下:
// 定义 NdIndexOffsetHelper 类来做多维张量的坐标映射
template
class NdIndexOffsetHelper {public:NdIndexOffsetHelper() = default;// 这段代码是一个构造函数模板,它的功能是根据给定的多维数组的维度初始化一个用于计算偏移量的辅助类。// 它的参数是一个可变参数模板,表示可以接受任意个数和类型的参数,但是第一个参数必须是一个T类型的值,// 后面的参数必须是一个参数包。它的函数体是一个调用另一个函数的语句,这个函数是用于初始化步长数组的。// 它使用了一个宏OF_DEVICE_FUNC,这个宏可能是用于指定函数在哪个设备上运行的,比如GPU或者CPU。// 这个构造函数模板可能是用于实现一些多维数组的操作,比如插值或者转置。templateOF_DEVICE_FUNC explicit NdIndexOffsetHelper(T d0, Ts... dims) {constexpr int n = 1 + sizeof...(dims);static_assert(n <= N, "");T dims_arr[n] = {d0, static_cast(dims)...};// 初始化strides信息InitStrides(dims_arr, n);}// 从一个类型为T的数组进行构造,并初始化strides信息,注意这里的strides长度设置为NOF_DEVICE_FUNC explicit NdIndexOffsetHelper(const T* dims) { InitStrides(dims, N); }// 从一个类型为U的数组进行构造,并初始化strides信息,注意这里的strides长度设置为NtemplateOF_DEVICE_FUNC explicit NdIndexOffsetHelper(const U* dims) {T dims_arr[N];for (int i = 0; i < N; ++i) { dims_arr[i] = dims[i]; }InitStrides(dims_arr, N);}// 从一个类型为T的数组进行构造,并初始化strides信息,注意这里的strides长度自定义为nOF_DEVICE_FUNC explicit NdIndexOffsetHelper(const T* dims, int n) { InitStrides(dims, n); }// 从一个类型为U的数组进行构造,并初始化strides信息,注意这里的strides长度自定义为ntemplateOF_DEVICE_FUNC explicit NdIndexOffsetHelper(const U* dims, int n) {T dims_arr[N];for (int i = 0; i < N; ++i) {if (i < n) { dims_arr[i] = dims[i]; }}InitStrides(dims_arr, n);}// virtual 表示这是一个虚析构函数,用于在删除基类指针时调用派生类的析构函数,避免内存泄漏。// ~NdIndexOffsetHelper() 表示这是 NdIndexOffsetHelper 类的析构函数,用于释放类对象占用的资源。// = default; 表示这是一个默认的析构函数,没有自定义的操作,让编译器自动生成。virtual ~NdIndexOffsetHelper() = default;// 这段代码是一个模板函数,用于根据一个N维索引数组计算一个一维偏移量。函数的参数和返回值都是模板类型T,可以是任意数值类型。函数的主要步骤如下:OF_DEVICE_FUNC T NdIndexToOffset(const T* index) const {// 定义一个变量offset,初始值为0,用于存储最终的偏移量。T offset = 0;
#ifdef __CUDA_ARCH__
#pragma unroll
#endif// 使用一个循环,从0到N-1,遍历索引数组的每一个元素。在循环中,使用一个数组stride_,// 用于存储每一个维度的步长,即每增加一个单位的索引,偏移量增加多少。// 将索引数组的第i个元素乘以步长数组的第i个元素,然后累加到offset上。for (int i = 0; i < N; ++i) { offset += index[i] * stride_[i]; }return offset;}// 类似上面,不过这里是从0到n进行循环OF_DEVICE_FUNC T NdIndexToOffset(const T* index, int n) const {assert(n <= N);T offset = 0;
#ifdef __CUDA_ARCH__
#pragma unroll
#endiffor (int i = 0; i < N; ++i) {if (i < n) { offset += index[i] * stride_[i]; }}return offset;}// 这段代码是一个函数模板,它的功能是根据给定的多维索引计算一个一维偏移量。// 它的参数是一个可变参数模板,表示可以接受任意个数和类型的参数,但是第一个// 参数必须是一个T类型的值,后面的参数必须是一个参数包。它的返回值也是一个T类型的值。// 它的函数体是一个循环,用于累加每个维度的索引乘以对应的步长,得到最终的偏移量。// 它使用了一个宏OF_DEVICE_FUNC,这个宏可能是用于指定函数在哪个设备上运行的,// 比如GPU或者CPU。这个函数模板可能是用于实现一些多维数组的操作,比如插值或者转置。templateOF_DEVICE_FUNC T NdIndexToOffset(T d0, Ts... others) const {constexpr int n = 1 + sizeof...(others);static_assert(n <= N, "");T index[n] = {d0, others...};T offset = 0;
#ifdef __CUDA_ARCH__
#pragma unroll
#endiffor (int i = 0; i < n - 1; ++i) { offset += index[i] * stride_[i]; }if (n == N) {offset += index[n - 1];} else {offset += index[n - 1] * stride_[n - 1];}return offset;}// 这段代码是一个成员函数模板,它的功能是根据给定的一维偏移量计算一个多维索引。// 它的参数是一个T类型的值,表示偏移量,和一个T类型的指针,表示索引数组。// 它的函数体是一个循环,用于逐个维度地计算索引值,然后更新剩余的偏移量。// 它使用了一个宏OF_DEVICE_FUNC,这个宏可能是用于指定函数在哪个设备上运行的,比如GPU或者CPU 。// 这个成员函数模板可能是用于实现一些多维数组的操作,比如插值或者转置。OF_DEVICE_FUNC void OffsetToNdIndex(T offset, T* index) const {T remaining = offset;
#ifdef __CUDA_ARCH__
#pragma unroll
#endiffor (int i = 0; i < N - 1; ++i) {const T idx = remaining / stride_[i];index[i] = idx;remaining = remaining - idx * stride_[i];}index[N - 1] = remaining;}// 这段代码是用C++语言编写的,它定义了一个名为OffsetToNdIndex的函数,// 该函数的功能是将一维的偏移量转换为高维的索引1。这个函数是OneFlow的内部类,// OneFlow是一个深度学习框架,它支持分布式训练和推理。这个函数的参数有三个,分别是:// offset: 一个整数,表示一维的偏移量。// index: 一个整数数组,用于存储转换后的高维索引。// n: 一个整数,表示高维的维度数,不能超过N,N是一个常量。// 函数的主要逻辑是:// 首先,用一个变量remaining存储offset的值。// 然后,用一个循环遍历从0到N-1的整数i。// 在循环中,如果i小于n,那么就用remaining除以stride_[i]得到一个整数idx,这个stride_[i]是一个预定义的数组,表示每个维度的步长。// 然后,将idx赋值给index[i],并用remaining减去idx乘以stride_[i],更新remaining的值。// 最后,结束循环。// 这个函数的作用是将一维的偏移量映射到高维的索引,这在深度学习中有很多应用,比如Unfold和Fold算子,它们可以将图像的局部区域转换为一维的向量,或者反过来。OF_DEVICE_FUNC void OffsetToNdIndex(T offset, T* index, int n) const {assert(n <= N);T remaining = offset;
#ifdef __CUDA_ARCH__
#pragma unroll
#endiffor (int i = 0; i < N; ++i) {if (i < n) {const T idx = remaining / stride_[i];index[i] = idx;remaining = remaining - idx * stride_[i];}}}// 它定义了一个名为OffsetToNdIndex的函数模板,该函数模板的功能和之前的函数类似,// 也是将一维的偏移量转换为高维的索引,但是它可以接受不同数量的参数。这个函数模板的参数有两个,分别是:// offset: 一个整数,表示一维的偏移量。// d0, others: 一系列的整数引用,用于存储转换后的高维索引。// 函数模板的主要逻辑是:// 首先,用一个常量n表示参数的个数,它等于1加上others的个数。// 然后,用一个静态断言检查n是否小于等于N,N是一个常量。// 然后,用一个指针数组index存储d0和others的地址。// 然后,用一个变量remaining存储offset的值。// 然后,用一个循环遍历从0到n-2的整数i。// 在循环中,如果i小于n-1,那么就用remaining除以stride_[i]得到一个整数idx,这个stride_[i]是一个预定义的数组,表示每个维度的步长。// 然后,将idx赋值给index[i]所指向的变量,并用remaining减去idx乘以stride_[i],更新remaining的值。// 最后,根据n和N的关系,分两种情况处理最后一个参数:// 如果n等于N,那么就将remaining赋值给index[n-1]所指向的变量。// 如果n小于N,那么就用remaining除以stride_[n-1]得到一个整数,赋值给index[n-1]所指向的变量。// 这个函数模板的作用是将一维的偏移量映射到高维的索引,它可以根据不同的参数个数进行重载,这是C++的一种泛型编程的特性templateOF_DEVICE_FUNC void OffsetToNdIndex(T offset, T& d0, Ts&... others) const {constexpr int n = 1 + sizeof...(others);static_assert(n <= N, "");T* index[n] = {&d0, &others...};T remaining = offset;
#ifdef __CUDA_ARCH__
#pragma unroll
#endiffor (int i = 0; i < n - 1; ++i) {const T idx = remaining / stride_[i];*index[i] = idx;remaining = remaining - idx * stride_[i];}if (n == N) {*index[n - 1] = remaining;} else {*index[n - 1] = remaining / stride_[n - 1];}}OF_DEVICE_FUNC constexpr int Size() const { return N; }protected:// 这段代码也是用C++语言编写的,它定义了一个名为InitStrides的函数,// 该函数的功能是初始化stride_数组,该数组表示每个维度的步长。这个函数的参数有两个,分别是:// dims: 一个整数数组,表示高维的维度大小。// n: 一个整数,表示高维的维度数,不能超过N,N是一个常量。// 函数的主要逻辑是:// 首先,用一个循环遍历从n-1到N-1的整数i。// 在循环中,将stride_[i]赋值为1。// 然后,用一个循环遍历从n-2到0的整数i。// 在循环中,将stride_[i]赋值为dims[i+1]乘以stride_[i+1]。// 这个函数的作用是计算每个维度的步长,这在之前的OffsetToNdIndex函数中有用到,它可以根据不同的维度大小和维度数进行初始化。OF_DEVICE_FUNC void InitStrides(const T* dims, const int n) {for (int i = n - 1; i < N; ++i) { stride_[i] = 1; }for (int i = n - 2; i >= 0; --i) { stride_[i] = dims[i + 1] * stride_[i + 1]; }}T stride_[N];
};
可以看到chatgpt不仅理解了NdIndexOffsetHelper是在做坐标映射,甚至把每个构造函数的功能以及涉及到的c++语法比如可变参数模板都给我们展示了。
看到这里,chatgpt已经帮助我们理解了BroadcastScaleMaskLoad/ElementwiseScaleMaskLoad这两个结构体类的功能和细节。基本没有出错,非常让我震撼。接下来,在fused_scale_mask_softmax的启动过程中还调用了一个广播维度简化的函数SimplifyBroadcastDims:https://github.com/BBuf/how-to-optim-algorithm-in-cuda/blob/master/oneflow-cuda-optimize-skills/fused_softmax/fused_scale_mask_softmax.cu#L2136 。我们来看看chatgpt是否可以合理的解释这个函数呢?
// 这个函数的功能是简化两个张量的广播维度,使它们能够进行算术运算。
// 广播是一种在不同形状的张量之间进行运算的方法,它会将较小的张量扩展到较大的张量的形状上。
// 这段代码的输入参数有:
// num_a_dims: 张量A的维度数
// a_dims: 张量A的每个维度的大小
// num_b_dims: 张量B的维度数
// b_dims: 张量B的每个维度的大小
// simplified_num_dims: 简化后的广播维度数
// simplified_a_dims: 简化后的张量A的每个维度的大小
// simplified_b_dims: 简化后的张量B的每个维度的大小
// 这段代码的主要逻辑是:
// 首先,找到两个张量的最大维度数,然后用一个闭包函数MakeGetDim来获取每个张量在每个维度上的大小,如果维度数不足,就用1来填充。
// 然后,遍历每个维度,计算两个张量在该维度上的最大值,作为广播后的维度大小。
// 如果该维度大小为1,就跳过,否则就判断是否可以和上一个维度合并,如果可以,就乘以上一个维度的大小,
// 如果不可以,就添加到简化后的维度数组中,并记录是否是广播维度。
// 最后,返回简化后的广播维度数和两个张量的简化后的维度大小。
// 这段代码的目的是为了减少广播运算的开销,提高深度学习的性能。
inline void SimplifyBroadcastDims(size_t num_a_dims, const int64_t* a_dims, size_t num_b_dims,const int64_t* b_dims, size_t* simplified_num_dims,int64_t* simplified_a_dims, int64_t* simplified_b_dims) {const size_t num_max_dims = std::max(num_a_dims, num_b_dims);auto MakeGetDim = [num_max_dims](size_t num_dims, const int64_t* dims) {const int64_t num_padding_dims = num_max_dims - num_dims;return [num_padding_dims, dims](size_t index) {return index < num_padding_dims ? 1 : dims[index - num_padding_dims];};};auto GetADim = MakeGetDim(num_a_dims, a_dims);auto GetBDim = MakeGetDim(num_b_dims, b_dims);*simplified_num_dims = 0;bool prev_broadcast_a = false;bool prev_broadcast_b = false;for (int64_t i = 0; i < num_max_dims; ++i) {const int64_t a_dim = GetADim(i);const int64_t b_dim = GetBDim(i);const int64_t broadcast_dim = std::max(a_dim, b_dim);// CHECK_GT(broadcast_dim, 0);const bool broadcast_a = (a_dim == 1);const bool broadcast_b = (b_dim == 1);// CHECK((a_dim == broadcast_dim) || broadcast_a);// CHECK((b_dim == broadcast_dim) || broadcast_b);if (broadcast_dim == 1) {continue;} else if (*simplified_num_dims != 0&& (prev_broadcast_a == broadcast_a && prev_broadcast_b == broadcast_b)) {simplified_a_dims[*simplified_num_dims - 1] *= a_dim;simplified_b_dims[*simplified_num_dims - 1] *= b_dim;} else {simplified_a_dims[*simplified_num_dims] = a_dim;simplified_b_dims[*simplified_num_dims] = b_dim;*simplified_num_dims += 1;prev_broadcast_a = broadcast_a;prev_broadcast_b = broadcast_b;}}
}
可以看到chatgpt给出的注释也是非常准确的,可以指出这段代码是为了减少广播运算的开销,提高深度学习的性能。
让chatgpt帮读代码到这里就结束了,BroadcastScaleMaskStore/ElementwiseScaleMaskStore的生成结果我也放到了 https://github.com/BBuf/how-to-optim-algorithm-in-cuda/blob/master/oneflow-cuda-optimize-skills/fused_softmax/fused_scale_mask_softmax.cu#L2136 。这次体验让我不得不感叹chatgpt的逻辑理解能力已经非常接近人类了,虽然写代码的能力相对还差一些但相信经过openai的数据以及参数迭代写代码的能力也将突飞猛进。
0x3. 性能表现
接着我们来实测一下这个fused_scale_mask_softmax的效果吧。就以Pattern这一节的代码为例子,使用nsight compute来观测一下fused_scale_mask_softmax相比于原始实现的性能。profile的代码如下:
import numpy as np
import oneflow as flowbatch_size = 4
num_heads = 8
seq_length = 64
broadcast_dim = 1
fill_value = -10000.0
scale_value = 2.0x = np.random.randn(batch_size, num_heads, seq_length, seq_length).astype(np.float32
)
mask_size = [batch_size, num_heads, seq_length, seq_length]
if broadcast_dim:mask_size[broadcast_dim] = 1mask = np.random.randint(0, 2, size=mask_size, dtype=bool)flow._oneflow_internal.profiler.RangePush('loop begin')
for i in range(100):fused_x_tensor = flow.tensor(x, dtype=flow.float32).to("cuda")fused_mask_tensor = flow.tensor(mask, dtype=flow.bool).to("cuda")flow._oneflow_internal.profiler.RangePush('fused_scale_mask_softmax')fused_out = flow._C.fused_scale_mask_softmax(fused_x_tensor, fused_mask_tensor, fill_value=fill_value, scale=scale_value,)flow._oneflow_internal.profiler.RangePop()origin_x_tensor = flow.tensor(x).to("cuda")origin_mask_tensor = flow.tensor(mask, dtype=flow.float32).to("cuda")flow._oneflow_internal.profiler.RangePush('origin scale mask softmax')origin_out = flow.mul(origin_x_tensor, origin_mask_tensor) * scale_value + fill_value * (1.0 - origin_mask_tensor)origin_out = flow.softmax(origin_out, dim=-1)flow._oneflow_internal.profiler.RangePop()
flow._oneflow_internal.profiler.RangePop()
assert(np.allclose(fused_out.numpy(), origin_out.numpy(), atol=1e-4, rtol=1e-4))
这里循环了100次计算并且使用内置api flow._oneflow_internal.profiler.RangePush/Pop来埋点。获得nsys文件之后使用NVIDIA Nsight Systems打开并进行分析。原始实现对应的时序图如红色框所示,计算一次的总时间大约100us:
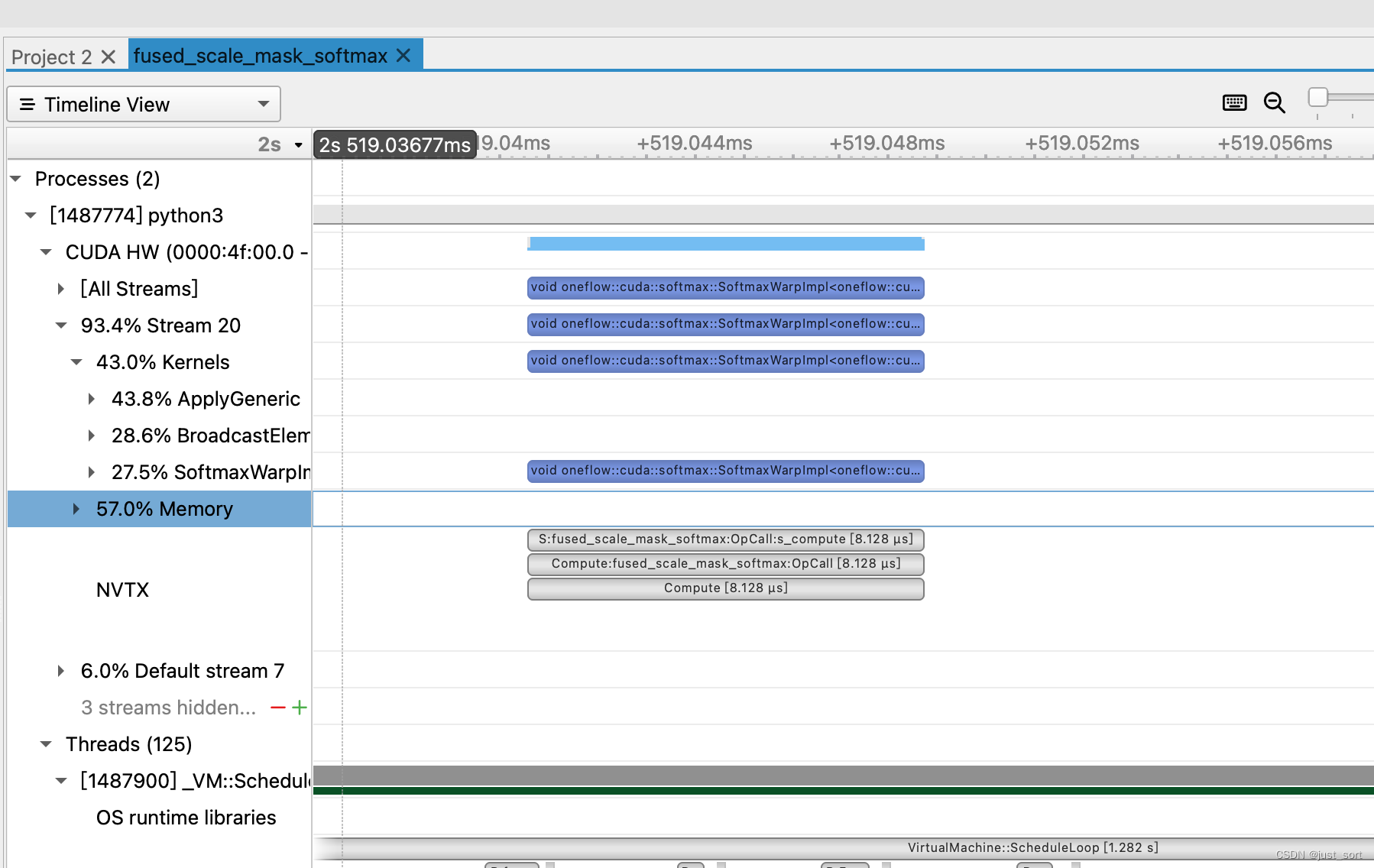
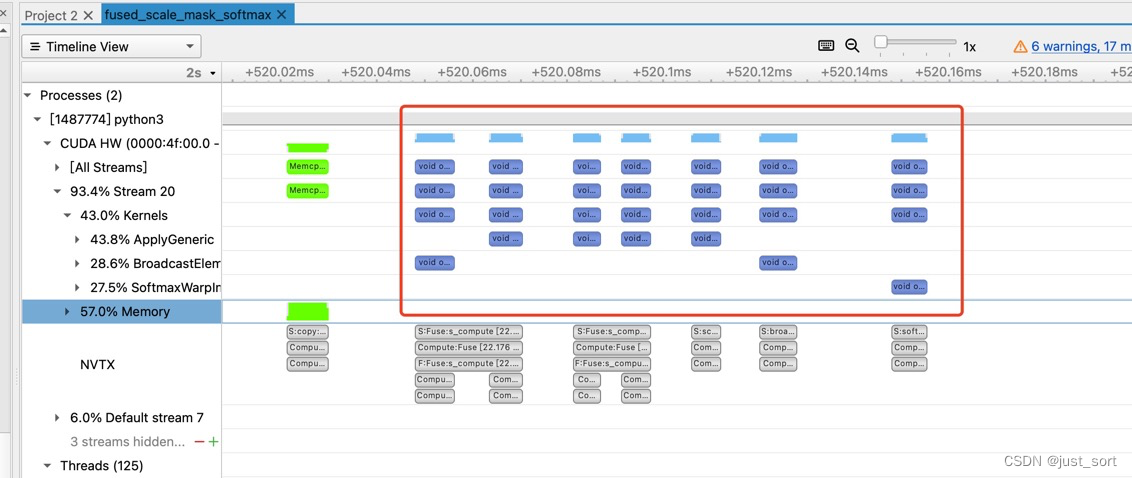 而用上fused_scale_mask_softmax之后的时序图如下所示,可以看到整个计算过程只有一个kernel并且只花了8个us,是非常大的性能提升。
而用上fused_scale_mask_softmax之后的时序图如下所示,可以看到整个计算过程只有一个kernel并且只花了8个us,是非常大的性能提升。
0x4. 总结
这篇文章展示了一下使用chatgpt阅读oneflow softmax相关的fuse优化(fused_scale_mask_softmax),在惊叹于chatgpt的代码逻辑理解能力的同时也可以体会到cuda中做kernel fuse相比于原始实现所能带来的性能优势。实际上这个fuse在attention中只是局部fuse,已经相对比较落后了。目前TensorRT/Xformers等都提供了多头注意力的完整fuse实现使得多头注意力部分的计算效率更高,oneflow中也集成了上述两种fmha的实现并且做了很多扩展提升易用性,后续有时间我将继续解读。