
PPYOLOE目标检测训练框架使用说明
创始人
2025-05-31 06:50:33
数据集准备
数据集标注参考博客【使用labelimg制作数据集】:https://blog.csdn.net/qq_41251963/article/details/111190442
标注数据注意事项,图片名称为纯数字,例如1289.jpg ;不要出现其他字符,否则下面代码转换会报错。
标注好的数据集格式为VOC格式,AI Studio 中PPYOLOE用到的数据格式为coco数据格式,需要将标注好的数据进行格式转换。执行python voc2coco.py 即可!转换代码如下:
voc2coco.py
import os
import random
import shutil
import sys
import json
import glob
import xml.etree.ElementTree as ET"""
代码来源:https://github.com/Stephenfang51/VOC_to_COCO
You only need to set the following three parts
1.val_files_num : num of validation samples from your all samples
2.test_files_num = num of test samples from your all samples
3.voc_annotations : path to your VOC dataset Annotations(最好写成绝对路径)"""
val_files_num = 0
test_files_num = 0
voc_annotations = r'C:/Users/liq/Desktop/VOC/Annotations/' #remember to modify the pathsplit = voc_annotations.split('/')
coco_name = split[-3]
del split[-3]
del split[-2]
del split[-1]
del split[0]
# print(split)
main_path = ''
for i in split:main_path += '/' + imain_path = main_path + '/'# print(main_path)coco_path = os.path.join(main_path, coco_name+'_COCO/')
coco_images = os.path.join(main_path, coco_name+'_COCO/images')
coco_json_annotations = os.path.join(main_path, coco_name+'_COCO/annotations/')
xml_val = os.path.join(main_path, 'xml', 'xml_val/')
xml_test = os.path.join(main_path, 'xml/', 'xml_test/')
xml_train = os.path.join(main_path, 'xml/', 'xml_train/')voc_images = os.path.join(main_path, coco_name, 'JPEGImages/')#from https://www.php.cn/python-tutorials-424348.html
def mkdir(path):path=path.strip()path=path.rstrip("\\")isExists=os.path.exists(path)if not isExists:os.makedirs(path)print(path+' ----- folder created')return Trueelse:print(path+' ----- folder existed')return False
#foler to make, please enter full pathmkdir(coco_path)
mkdir(coco_images)
mkdir(coco_json_annotations)
mkdir(xml_val)
mkdir(xml_test)
mkdir(xml_train)#voc images copy to coco images
for i in os.listdir(voc_images):img_path = os.path.join(voc_images + i)shutil.copy(img_path, coco_images)# voc images copy to coco images
for i in os.listdir(voc_annotations):img_path = os.path.join(voc_annotations + i)shutil.copy(img_path, xml_train)print("\n\n %s files copied to %s" % (val_files_num, xml_val))for i in range(val_files_num):if len(os.listdir(xml_train)) > 0:random_file = random.choice(os.listdir(xml_train))# print("%d) %s"%(i+1,random_file))source_file = "%s/%s" % (xml_train, random_file)if random_file not in os.listdir(xml_val):shutil.move(source_file, xml_val)else:random_file = random.choice(os.listdir(xml_train))source_file = "%s/%s" % (xml_train, random_file)shutil.move(source_file, xml_val)else:print('The folders are empty, please make sure there are enough %d file to move' % (val_files_num))breakfor i in range(test_files_num):if len(os.listdir(xml_train)) > 0:random_file = random.choice(os.listdir(xml_train))# print("%d) %s"%(i+1,random_file))source_file = "%s/%s" % (xml_train, random_file)if random_file not in os.listdir(xml_test):shutil.move(source_file, xml_test)else:random_file = random.choice(os.listdir(xml_train))source_file = "%s/%s" % (xml_train, random_file)shutil.move(source_file, xml_test)else:print('The folders are empty, please make sure there are enough %d file to move' % (val_files_num))breakprint("\n\n" + "*" * 27 + "[ Done ! Go check your file ]" + "*" * 28)# !/usr/bin/python# pip install lxmlSTART_BOUNDING_BOX_ID = 1
PRE_DEFINE_CATEGORIES = None# If necessary, pre-define category and its id
# PRE_DEFINE_CATEGORIES = {"aeroplane": 1, "bicycle": 2, "bird": 3, "boat": 4,
# "bottle":5, "bus": 6, "car": 7, "cat": 8, "chair": 9,
# "cow": 10, "diningtable": 11, "dog": 12, "horse": 13,
# "motorbike": 14, "person": 15, "pottedplant": 16,
# "sheep": 17, "sofa": 18, "train": 19, "tvmonitor": 20}"""
main code below are from
https://github.com/Tony607/voc2coco
"""def get(root, name):vars = root.findall(name)return varsdef get_and_check(root, name, length):vars = root.findall(name)if len(vars) == 0:raise ValueError("Can not find %s in %s." % (name, root.tag))if length > 0 and len(vars) != length:raise ValueError("The size of %s is supposed to be %d, but is %d."% (name, length, len(vars)))if length == 1:vars = vars[0]return varsdef get_filename_as_int(filename):try:filename = filename.replace("\\", "/")filename = os.path.splitext(os.path.basename(filename))[0]return int(filename)except:raise ValueError("Filename %s is supposed to be an integer." % (filename))def get_categories(xml_files):"""Generate category name to id mapping from a list of xml files.Arguments:xml_files {list} -- A list of xml file paths.Returns:dict -- category name to id mapping."""classes_names = []for xml_file in xml_files:tree = ET.parse(xml_file)root = tree.getroot()for member in root.findall("object"):classes_names.append(member[0].text)classes_names = list(set(classes_names))classes_names.sort()return {name: i for i, name in enumerate(classes_names)}def convert(xml_files, json_file):json_dict = {"images": [], "type": "instances", "annotations": [], "categories": []}if PRE_DEFINE_CATEGORIES is not None:categories = PRE_DEFINE_CATEGORIESelse:categories = get_categories(xml_files)bnd_id = START_BOUNDING_BOX_IDfor xml_file in xml_files:tree = ET.parse(xml_file)root = tree.getroot()path = get(root, "path")if len(path) == 1:filename = os.path.basename(path[0].text)elif len(path) == 0:filename = get_and_check(root, "filename", 1).textelse:raise ValueError("%d paths found in %s" % (len(path), xml_file))## The filename must be a numberimage_id = get_filename_as_int(filename)size = get_and_check(root, "size", 1)width = int(get_and_check(size, "width", 1).text)height = int(get_and_check(size, "height", 1).text)image = {"file_name": filename,"height": height,"width": width,"id": image_id,}json_dict["images"].append(image)## Currently we do not support segmentation.# segmented = get_and_check(root, 'segmented', 1).text# assert segmented == '0'for obj in get(root, "object"):category = get_and_check(obj, "name", 1).textif category not in categories:new_id = len(categories)categories[category] = new_idcategory_id = categories[category]bndbox = get_and_check(obj, "bndbox", 1)xmin = int(get_and_check(bndbox, "xmin", 1).text) - 1ymin = int(get_and_check(bndbox, "ymin", 1).text) - 1xmax = int(get_and_check(bndbox, "xmax", 1).text)ymax = int(get_and_check(bndbox, "ymax", 1).text)assert xmax > xminassert ymax > ymino_width = abs(xmax - xmin)o_height = abs(ymax - ymin)ann = {"area": o_width * o_height,"iscrowd": 0,"image_id": image_id,"bbox": [xmin, ymin, o_width, o_height],"category_id": category_id,"id": bnd_id,"ignore": 0,"segmentation": [],}json_dict["annotations"].append(ann)bnd_id = bnd_id + 1for cate, cid in categories.items():cat = {"supercategory": "none", "id": cid, "name": cate}json_dict["categories"].append(cat)os.makedirs(os.path.dirname(json_file), exist_ok=True)json_fp = open(json_file, "w")json_str = json.dumps(json_dict)json_fp.write(json_str)json_fp.close()xml_val_files = glob.glob(os.path.join(xml_val, "*.xml"))
xml_test_files = glob.glob(os.path.join(xml_test, "*.xml"))
xml_train_files = glob.glob(os.path.join(xml_train, "*.xml"))convert(xml_val_files, coco_json_annotations + 'val2017.json')
convert(xml_test_files, coco_json_annotations+'test2017.json')
convert(xml_train_files, coco_json_annotations + 'train2017.json')Fork PPYOLOE项目并启动运行
PPYOLOE目标检测训练框架
https://aistudio.baidu.com/aistudio/projectdetail/5756078
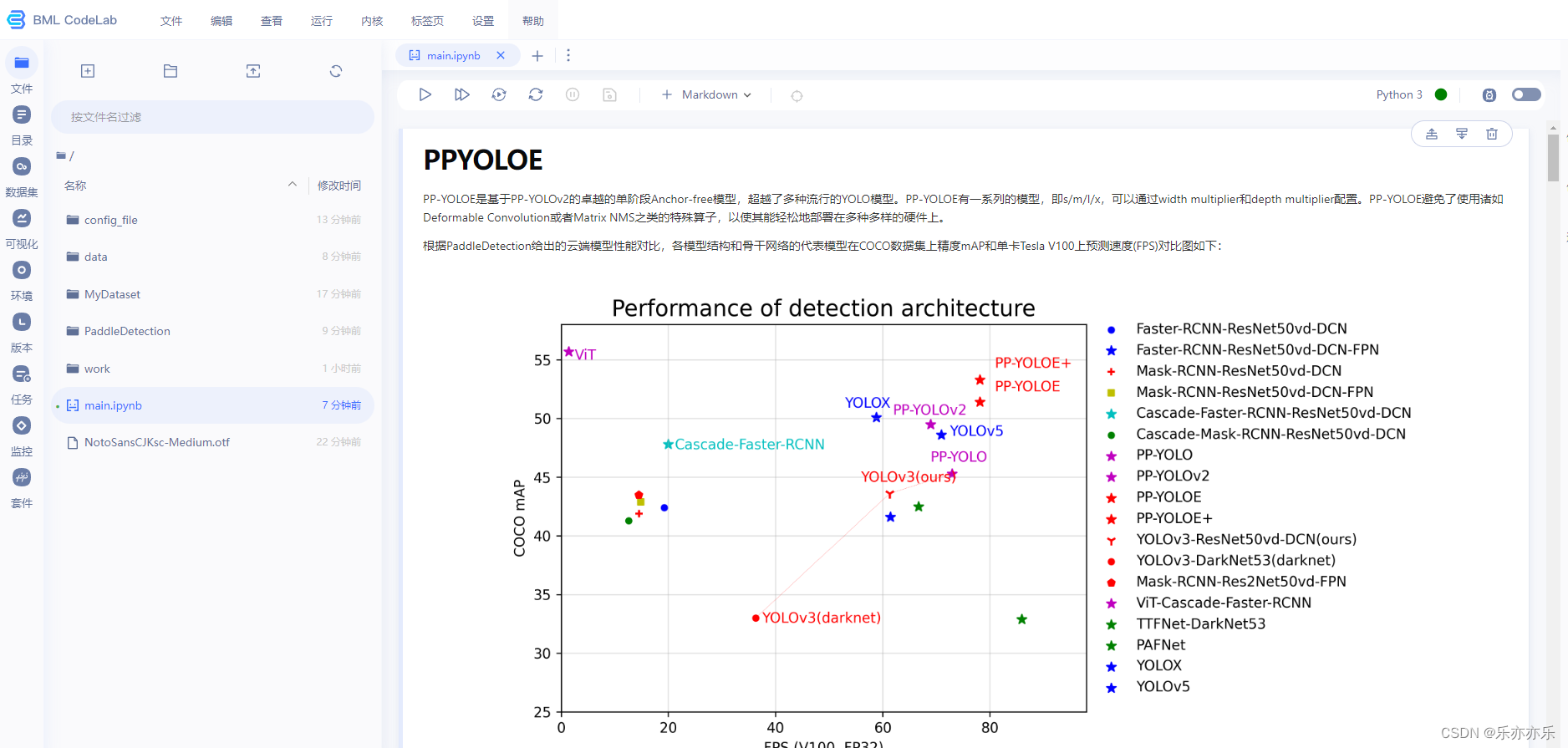
按照main.ipynb流程依次执行即可!
导入所需要的第三方库
安装paddlex
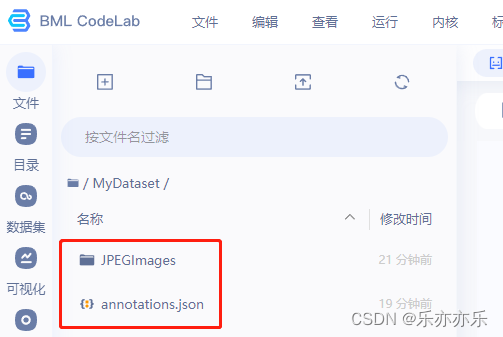
创建数据集目录 将标注的图像数据上传到 MyDataset/JPEGImages 目录下;将coco格式数据标签annotations.json放到MyDataset目录下。
按比例切分数据集
git PaddleDetection代码
进入PaddleDetection目录
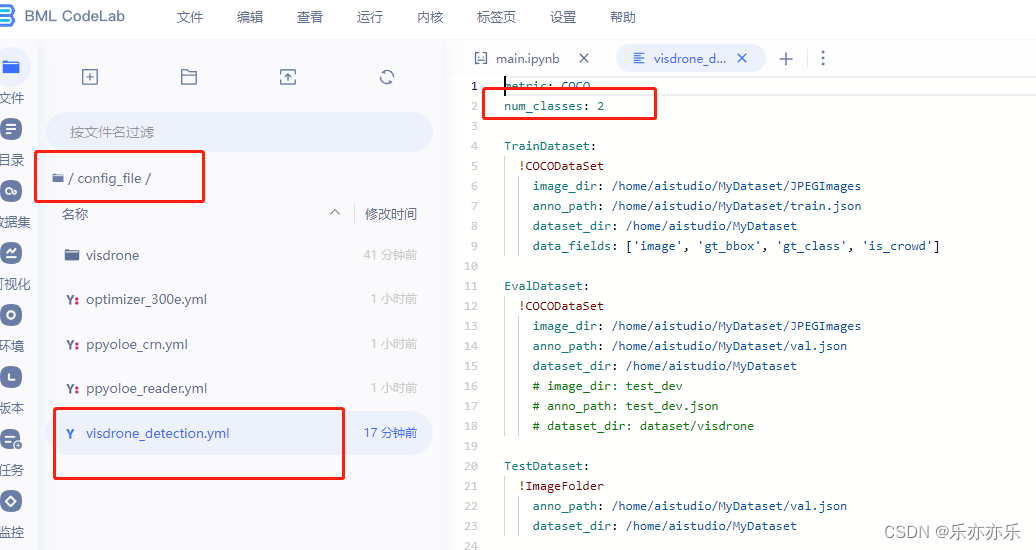
根据需求修改配置文件,比如检测的目标类别数 进入/home/aistudio/config_file/目录下,修改visdrone_detection.yml中num_classes参数
开始训练
训练完成后评估模型
挑一张验证集的图片展示预测效果(可以到生成的目录下,打开查看)
导出模型,即可使用FastDeploy进行快速推理
相关内容
热门资讯
量身定做自己的幸福高三作文(...
量身定做自己的幸福高三作文 篇一我相信每个人都有自己对幸福的定义,对于高三学生来说,幸福会有着不同的...
写给高三同学的箴言【经典3篇...
写给高三同学的箴言 篇一挥洒汗水,收获辉煌亲爱的高三同学们:转眼间,你们已经踏入高三这个紧张而重要的...
高三考生巧记英语单词的四大妙...
高三考生巧记英语单词的四大妙招 篇一在高三备考期间,英语单词的记忆是必不可少的一部分。然而,面对众多...
人生如逆旅高二作文【实用6篇...
人生如逆旅高二作文 篇一人生如逆旅,充满了未知和变数。我们每个人都在这条旅途中前行,经历着各种各样的...
你一直都在高三作文【精选3篇...
你一直都在高三作文 篇一我的高三生活高三,是我人生中最为艰难的一年。从开学的那一刻起,我就意识到了这...