【半监督学习】5、Efficient Teacher | 专为 one-stage anchor-based 方法设计的半监督目标检测方法

文章目录
- 一、背景
- 二、方法
- 2.1 Dense Detector
- 2.2 Pseudo Label Assigner
- 2.3 Epoch Adaptor
- 三、效果
论文:Efficient Teacher: Semi-Supervised Object Detection for YOLOv5
出处:阿里
时间:2023.03
一、背景
目标检测近年来的进展离不开大量的标注数据,但数据标识昂贵且耗时。
故此,半监督方法被提出,通过自动生成伪标签来利用大量的未标注数据。
目前的半监督学习有如下三个最重要的挑战:
- 第一,半监督目标检测(Semi-supervised Object Detection, SSOD)在 RCNN 和 anchor-free 系列检测器(如 FCOS)上都有了较为成功的应用,但在单阶段 anchor-based 方法上海有些欠缺,主要表现在生成高质量且灵活的伪标签能力较弱。其原因在于单阶段 anchor-based 检测器会产生很多的 anchor 用于密集预测,导致监督训练时正负样本不平衡,半监督训练中伪标签的质量较差
- 第二,当前主流的 SSOD 方法,主要使用 teacher-student 的方式 [21, 35]。但单阶段 anchor-based 方法由于教师模型生成的伪标签数量和质量都有很大的波动,劣质的伪标签会导致模型效果变差,所以难以训练,[37] 证明了 RetinaNet 在 SSOD 上的效果就没有 Faster RCNN 和 FCOS 好
- 第三,现有的方法大都为了追求准确性而牺牲了训练效率,所以无法兼顾效果和速度,但效率和速度的平衡也非常重要
本文提出了可扩展的针对 one-stage anchor-based SSOD 的训练框架,同时考虑推理和训练效率。
包括密集检测器、伪标签 assigner、epoch 适配器等等。
作者将 YOLO 系列中的很多高效的思想应用在了 RetinaNet 中,基于 RetinaNet 设计了一个典型的 one-stage anchor-based detector baseline —— Dense Detector。
贡献点:
- 设计了一个 Dense Detector 作为 baseline
- 提出了一个高效的 SSOD 训练框架——Efficient Teacher,其中 Pseudo Label Assigner 用于减少伪标签的不一致性, Epoch Adaptor 用于提高端到端的训练效率
- Efficient Teacher 在 YOLOv5 上获得了 VOC 和 COCO 数据集 SOTA 效果
二、方法
Efficient Teacher 是用于提高 one-stage anchor-based 检测器在半监督目标检测上的效果的方法。
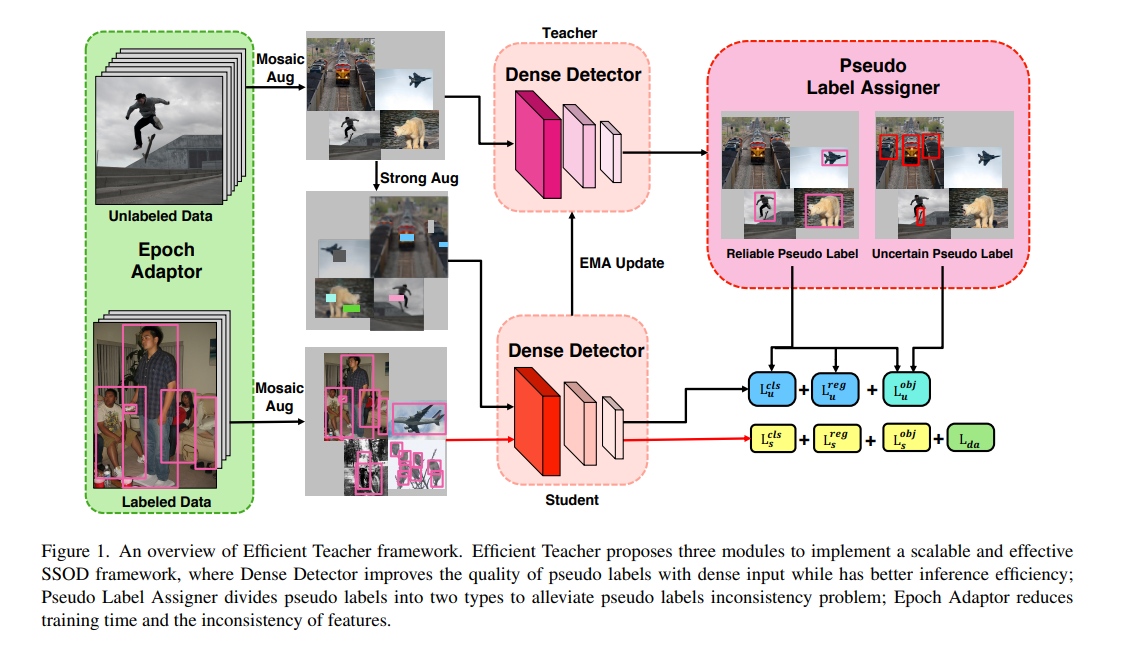
其框架也是 student-teacher 的框架,如图 1 所示。
-
学生网络:接收两部分数据:
- 经过 Mosaic 数据增强的带标签数据,使用有监督学习来训练,包括分类 loss、回归 loss、obj loss、域自适应 loss
- 经过 Mosaic 数据增强和 Strong 数据增强的无标签数据,使用伪标签来训练,包括分类 loss、回归 loss、obj loss
-
教师网络:接收使用 Mosaic 数据增强的无标签数据,预测的结果用于指导学生模型的训练
-
Pseudo Label Assigner method: 根据 pseudo label 的分类得分将其分为 reliable 和 uncertain
- reliable 表示可靠的 label,用于有监督学习,参与分类 loss、回归 loss、obj loss 的计算
- uncertain 表示不确定的 label,使用 soft loss 来 训练 student model,也就是只有 obj>0.99 的参与 obj loss 的计算
-
Epoch Adaptor method: 通过对已标注数据和未标注数据进行域自适应和分布自适应,并且会自主计算每个 epoch 中的 pseudo label 的 PLA 标签划分的阈值,来加速网络收敛
-
教师模型是学生模型通过 EMA 更新得到的
2.1 Dense Detector
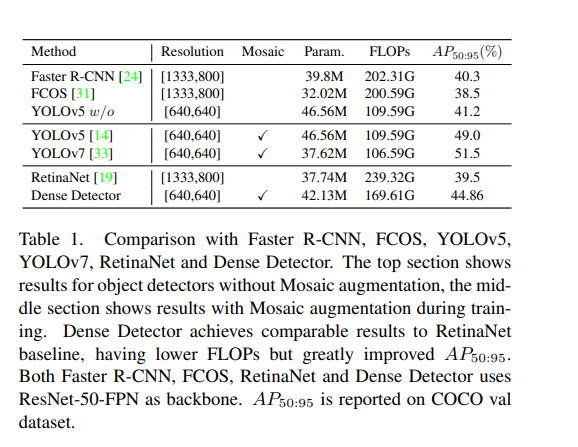
表 1 展示了 YOLOv5 with/without 在性能和计算量上都优于 RetinaNet
- 使用 mosaic 增强,YOLOv5 的 AP50:95 从 41.2 提升到了 49%
- YOLOv7 通过对密集特征流和梯度的改进,进一步提升到了 51.5%
- 所以,作者认为增加输入密度可以有效提高 one-stage anchor-based 检测器的效果,也构建了 Dense Detector 来证明
Dense Detector 的结构:
- 从 RetinaNet with ResNet-50-FPN 改进而来
- 将 FPN 的输出层从 5 改成了 3,且不同层级的 head 没有共享权重
- 训练和推理时的输入分辨率从 1333 变成了 640
- 有三个输出分支:分类、回归偏移、objectness
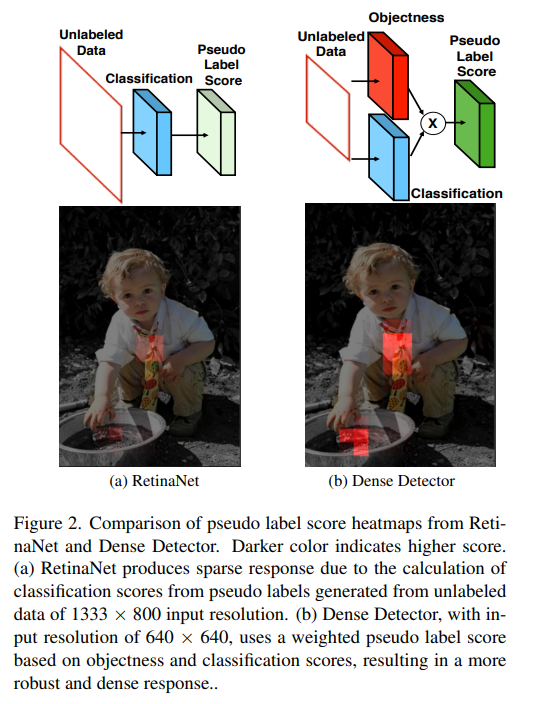
- objectness:预测和 gt 之间的 CIoU,其得分表示预测 box 的质量,可以作为额外的信息来提高检测效果
- 如图 1 所示,objectness score 能够表示伪标签框的定位质量,所以,相比于 RetinaNet 只使用分类得分来表示框的质量,Dense Detector 能够在训练时使用 objectness score 来表示框的质量(如图 2 所示,Dense Detector 能够在使用小分辨率输入的情况下,基于 objectness 和 cls score 来得到更强的伪标签响应)
Dense Detector 和 RetinaNet 的效果比较:
- Dense Detector 提升了 5.36% 的 AP50:95
- 推理速度快了 30%
2.2 Pseudo Label Assigner
SSOD 还有一个很重要的模块就是正负样本分配
如果简单的使用阈值来分配的话,比如大于 IoU 阈值的伪标签被分为正样本,小于 IoU 阈值的被分为负样本,就会导致错误的分配
如图 3 所示,上半部分中,是使用阈值过滤,保留高于阈值得分的伪标签,在整个训练过程中,伪标签的分数可能会持续增加,导致无法收敛。
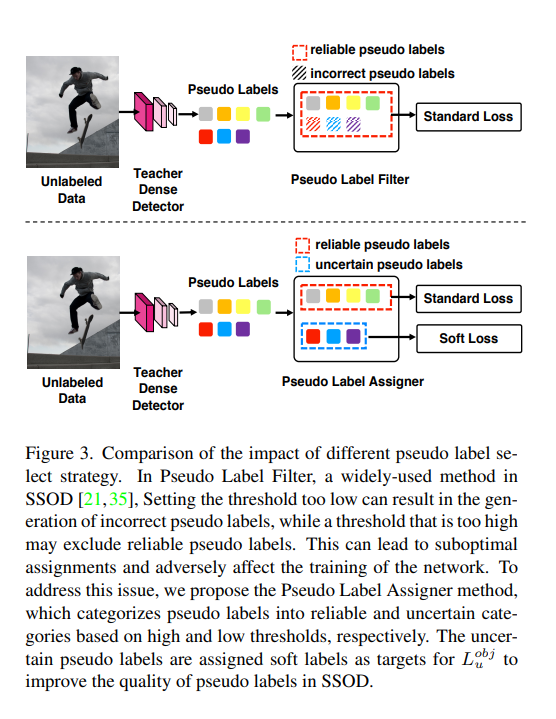
本文提出了 Pseudo Label Assigner(PLA),是一个更精细的伪标签分配器。
核心在于:
- 在 NMS 后,使用 低阈值 τ1\tau_1τ1 和 高阈值 τ2\tau_2τ2 (论文中高低貌似写反了),将获得的伪标签分为 reliable 和 uncentain 两个类别
- uncertain:处于两个阈值中间的 label 认为是不确定的
- reliable:大于高阈值的 label 认为是可信的
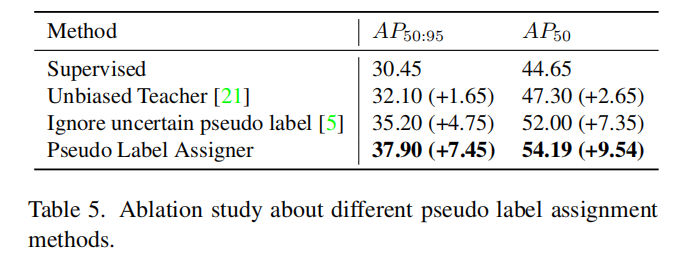
一般的方法对于 uncertain label 的处理方式基本上都是不参与 loss 的计算,来提高模型的效果,如表 5 所示。
但 PLA 中使用了一个无监督的损失,有效的利用了 uncertain 的伪标签
下面从 loss 层面来看作者是如何利用 uncertain label 的:
Dense Detector 的 loss 是 labeled data 和 unlabeled data 之和:
- LsL_sLs 是 labeled data 的 loss
- LuL_uLu 是 unlabeled data 的 loss
- λ=3\lambda=3λ=3 用于平衡两个 loss。
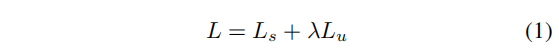
LsL_sLs 的公式如下:
- 是所有标签数据的分类、回归、objectness loss 之和:
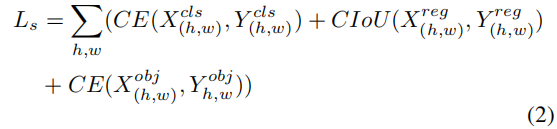
- X(h,w)X_{(h, w)}X(h,w) 是 student model 的输出
- Y(h,w)Y_{(h, w)}Y(h,w) 是 label assigner 的结果
- 分类损失:使用二值交叉熵损失来计算,计算的是学生网络的输出和教师网络的输出的二值交叉熵损失
- 回归损失:使用 CIoU loss 来计算
- objectness 损失:使用二值交叉熵损失来计算
LuL_uLu 公式如下:
-
也包括分类、回归、objectness 损失共三个部分,按伪标签的分类得分和 objectness 得分来决定其是否需要参与 loss 计算
-
伪标签的可信度是按低阈值 τ1\tau_1τ1 和高阈值 τ2\tau_2τ2 划分的,在 τ1\tau_1τ1 和 τ2\tau_2τ2 之间为 uncertain label
-
分类 loss:当伪标签的分类 score >= τ2\tau_2τ2 时,即所有的 reliable label,计算其分类 loss
-
回归 loss:当伪标签的分类 score >= τ2\tau_2τ2 或 objectness score > 0.99 时,即所有的 reliable label 和所有 objectness 非常高即定位很准的 label,计算其回归 loss
-
objectness loss:
- 当伪标签的分类 score <= τ1\tau_1τ1 时,按 objectness 真值为 0 来计算预测的 obj 的 loss,也就是期望这些低于高阈值的 uncertain label 的 objectness = 0
- 当伪标签的分类 score >= τ2\tau_2τ2 时,也就是 reliable label,按 objectness 真值 来计算预测的 obj 的 loss
- 当伪标签的分类 τ1\tau_1τ1 < score < τ2\tau_2τ2 时,也就是 uncertain label,这种 label 按 soft label objh,w^\hat{obj_{h,w}}objh,w^ 来计算预测的 obj 的 loss

- Y^(h,w)cls\hat{Y}_{(h,w)}^{cls}Y^(h,w)cls 是位置 (h, w) 上经过 PLA 得到的结果的分类得分
- Y^(h,w)reg\hat{Y}_{(h,w)}^{reg}Y^(h,w)reg 是位置 (h, w) 上经过 PLA 得到的结果的回归得分
- Y^(h,w)obj\hat{Y}_{(h,w)}^{obj}Y^(h,w)obj 是位置 (h, w) 上经过 PLA 得到的结果的 objectness 得分
- obj^h,w\hat{obj}_{h,w}obj^h,w 是位置 (h, w) 上的 pseudo label 的 objectness score,也是 soft label
- p(h,w)p_{(h,w)}p(h,w) 是 pseudo label 的分类 score
- 1{.}1_{\{.\}}1{.} 是指示函数
PLA 和其他方法的区别在于,作者设计了一个 soft loss 来专门解决 uncertain pseudo label。
PLA 将 uncertain pseudo label 分成了两个类别:
-
高分类得分的 uncertain pseudo label:只参与计算 objectness loss
只计算 objectness loss LuobjL_u^{obj}Luobj,使用 soft label obj^h,w\hat{obj}_{h,w}obj^h,w 来替换 Y^(h,w)obj\hat{Y}(h,w)^{obj}Y^(h,w)obj 作为 cross-entropy 的学习目标。
因为不会参与分类和回归 loss 的计算,所以这些伪标签不会被分为正样本或负样本
-
高 objectness 得分的 uncertain pseudo label:只参与计算 reg loss
当 objectness score > 0.99 时,计算回归 loss LuregL_u^{reg}Lureg,不计算分类 loss
因为这些伪标签的回归结果很好,但不一定有很好的分类结果,所以不计算分类 loss。
PLA 使用 LuregL_u^{reg}Lureg 将伪标签转换为 TP,因为在 COCO 上训练 SSOD 时,大于 70% 的 uncertain 伪标签都是 FP,因为它们定位都很不准确。
所以,PLA 能通过 soft label 的方式一致这些分类和回归效果不一致的伪标签,且没有影响 reliable 伪标签的 loss。
2.3 Epoch Adaptor
SSOD 中还有一个严峻的问题就是在训练时的效率
作者引入 Epoch Adaptor,使用域自适应和分布自适应方法来让 SSOD 的训练更快速更平稳。
Epoch Adaptor 的目的:
- 域自适应:缩小有标签数据和无标签数据的分布差距
- 分布自适应:动态的估计每个 epoch 的伪标签的阈值
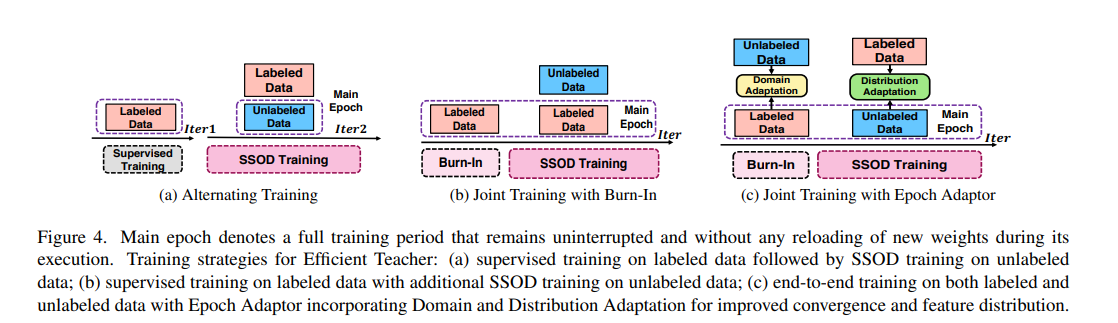
1、域自适应:缓解模型对带标签数据的过拟合,对带标签数据的 loss 中又引入了一个域自适应 loss
如图 4 所示,EA 能够使得神经网络在 Burn-In 阶段同时接收有标签和无标签的数据,使用带分类器的域自适应放来限制检测器区分这两种类型数据的能力,这能够有效的减轻过拟合,且该方法仅依赖于 Burn-In 阶段的带标签数据。
域自适应 loss 函数如下:
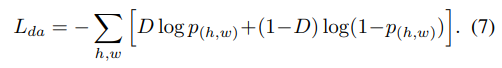
- p(h,w)p_{(h,w)}p(h,w) 是 domain classifier 的输出
- 有标签数据的 D=0,无标签数据的 D=1
使用 gradient reverse layer(GRL),普通的梯度下降用于训练 domain classifier,在经过 GRL 时梯度的符号会反转来优化基础网络
在 Burn-In 阶段,一个图像中的有监督 loss 如下:
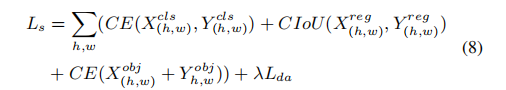
- λ\lambdaλ 是超参数,设置为 0.1
一般情况下,阈值 τ1\tau_1τ1 和 τ2\tau_2τ2 是需要计算的,来帮助 SSOD 在训练期间更好的获得需要的伪标签
2、分布自适应:在每个 epoch 自适应地计算合适的阈值来区分 reliable 和 uncertain pseudo label
[4] 中需要使用带标签数据的标签分布的先验信息来计算阈值
但是作者前面已经证明了 Mosaic 数据增强的效果,所以,作者使用 Mosaic 数据增加来破坏标签分布比率
提出了一种基于重分布的分布自适应的方法 LabelMatch[4] 的方法
在分布自适应中,第 k 个 epoch 的阈值为:
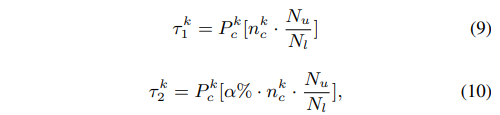
- reliable reatio α=60\alpha=60α=60
- PckP_c^kPck 是第 c 个类别在第 k 个 epoch 上的伪标签得分
- NlN_lNl 和 NuN_uNu 表示带标签数据量和不带标签数据量
- nckn_c^knck 表示第 k 个 epoch 在第 c 个类别上由 EA 计算得到的 gt 标注的数量
EA 中提出的 domain adaptation 和 distribution adaptation 的效果:
- 很好的缓解了神经网络对带标签数据的过拟合
- 在每个 epoch 为伪标签估计合适的阈值,实现快速且高效的训练
三、效果
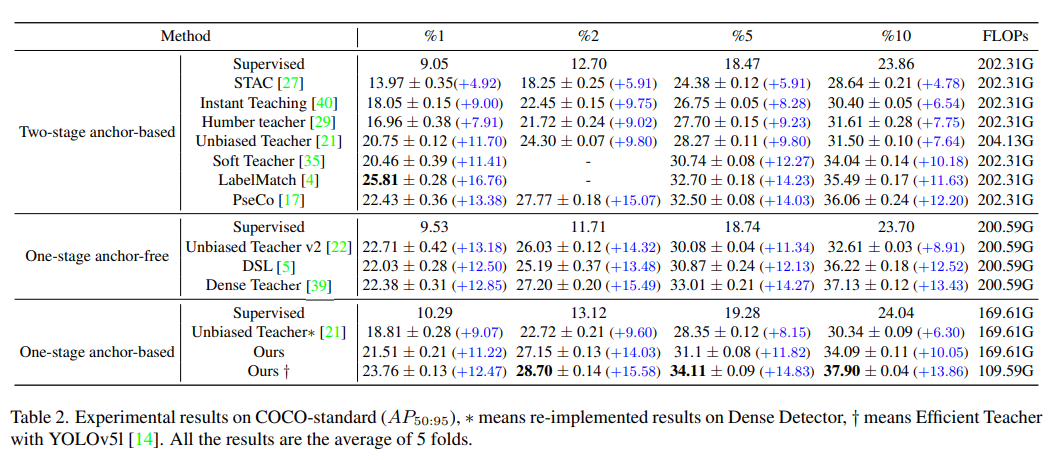
1、在 COCO-standard 上的效果
- 本文方法优于 Unbiased Teacher 方法
- 在 tow-stage anchor-based 和 one-stage anchor-free 的 SSOD 方法中,Efficient Teacher 获得了与 SOTA 方法相当的提升
- 使用 YOLOv5l 作为 Dense Detector 的 backbone 时,能够在计算开销小的情况下获得好的检测性能
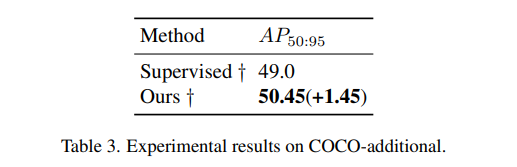
2、在 COCP-additional 的效果
- 提升了 1.45
- 说明在 YOLOv5l 使用监督训练的情况下,还可以使用 Efficient Teacher 对其提升,因为可以在训练中引入未标记数据和伪标签,能够减轻对标记数据的过拟合,提升模型的泛化性
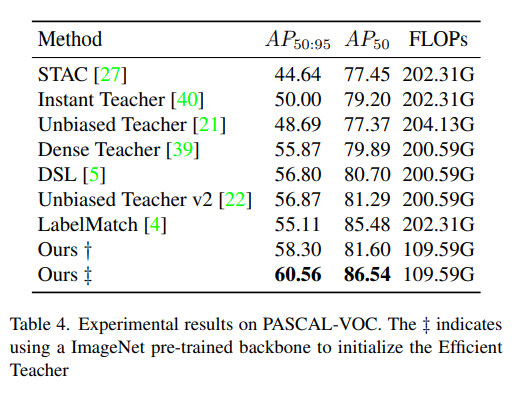
3、在 Pascal VOC 上的效果
4、PLA 的效果如表 5 所示:
- 如果使用 Unbiased Teacher 的方法用于 Dense Teacher,阈值为 0.3 是,AP50:95 会提升 1.65
- 将 Unbiased Teacher 的方法用于 Faster RCNN 时,AP50:95 会提升 7.6
- 当忽略 uncertain pseudo label 时,AP50:95 会降低到 35.2
- 使用 PLA 来处理 uncertain label 时,AP50:95 会提升 7.45,达到 37.9,和在 Faster RCNN 上使用 Unbiased Teacher 能够获得类似的提升

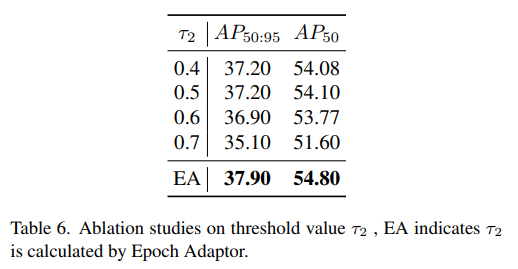
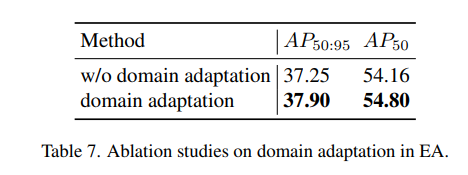
5、EA 的效果
在 EA 中使用 distribution adaptation 的效果如表 6:
- 提升 τ2\tau_2τ2 会降低 AP50:95,因为提高了后就会产生很多 uncertain label,很少的 reliable label,所以如何保持两种 label 的平衡对模型也很重要
- 在使用自适应获取阈值的情况下,能够自主计算合适的阈值,就可以产生更合适的 label,帮助模型提升效果
使用 domain adaptation 能够为无标签数据生成更好的伪标签
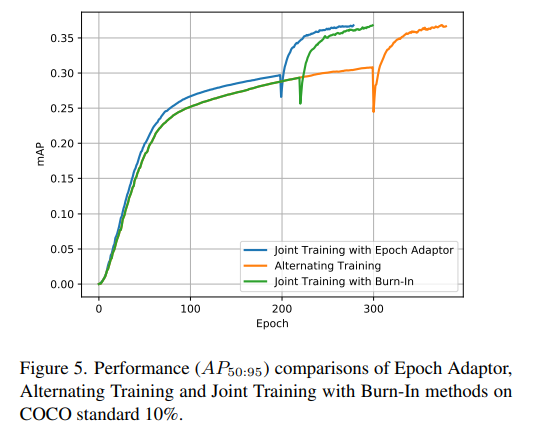
EA 的加速效果如下图所示,蓝色线可以直观看出来训练效果更好,收敛更快