
csapp第三章(1) --- 程序的机器级表示
csapp第二章 --- 信息的表示和处理 https://blog.csdn.net/m0_63488627/article/details/129271452?spm=1001.2014.3001.5501
https://blog.csdn.net/m0_63488627/article/details/129271452?spm=1001.2014.3001.5501
本章大纲
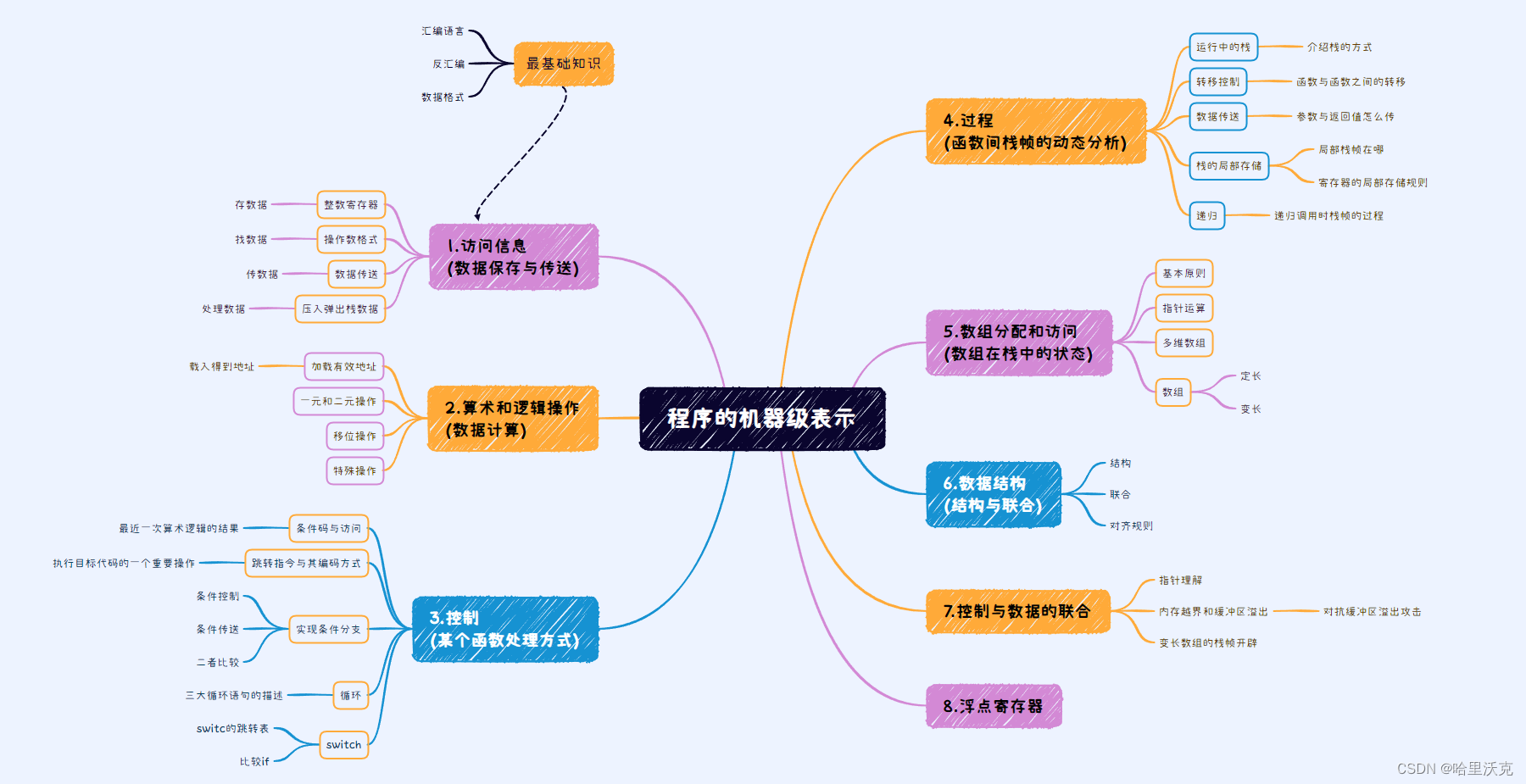
目录
基础知识介绍
1.汇编语言
2.反汇编
3.数据格式
3.1.访问信息
3.1.1整数寄存器介绍
3.1.2操作数格式
3.1.3数据传输
3.1.4压入弹出栈数据
3.2.算术和逻辑操作
3.2.1.加载有效地址
3.2.2.一元和二元操作
3.2.3.移位操作
3.2.4特殊的算术操作
3.3.控制
3.3.1条件码
3.3.2跳转指令与其编码方式
3.3.3条件语句
3.3.4循环
3.3.5switch语句
基础知识介绍
1.汇编语言
汇编语言是用于转换成二进制语言的。介于源代码和机器语言之间,人们可以读懂之,并且也能了解编译器翻译后最接近二进制的语言,为后面的理解运行提供基础

2.反汇编
源代码直接转成汇编语言时,不会提供给人看的路径。但是我们可以先转成二进制语言,二进制文件能够被看到,但是看不懂,这时我们可以通过操作系统提供的反汇编指令使得二进制变成汇编语言的文件,方便查看。
gcc -Og -c mstore.c
这条指令,意思是将代码变成.exe文件,其中-Og是一种编译方式,不同的代表不同优化方式,优化越高,代码与源代码越不接近,-Og便是最小优化的编译方式
objdump -d mstore.c
反汇编指定的文件
3.数据格式
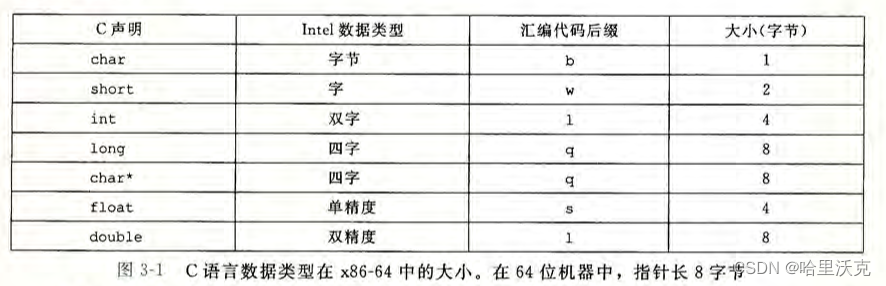
3.1.访问信息
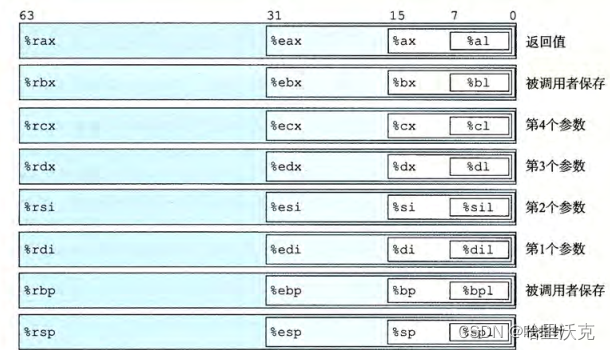
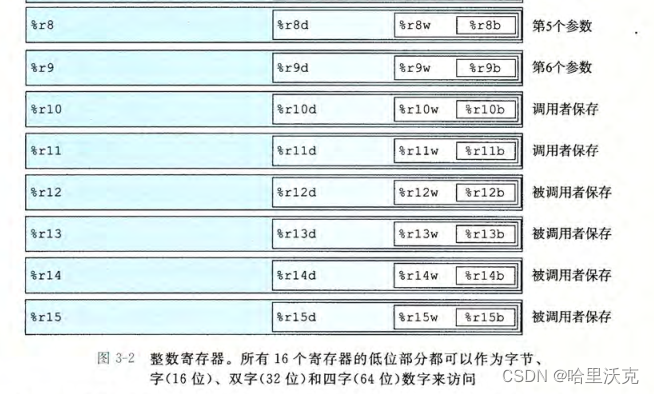
3.1.1整数寄存器介绍
寄存器有64位空间,但是会根据描述和对应的寄存器决定存储几位。
1.对于1字节和1字的寄存器,就将数据存对应位即可
2.对于2字的寄存器,针对64位中前32位都置为0,后32位描述数据
%rax:保存函数的返回值
%rbx:被调用者保存意思就是被调用的函数来执行存储原先寄存器数据的义务
%rbp:基指针,用来存储栈中一个位置的指针
%rsp:保存程序栈的结束位置
3.1.2操作数格式
前面讲数据有的存储在寄存器中,多大的数据使用怎么样的寄存器。
现在我们需要知道这些数据被存放好后,到底是如何找寻的。而这种被指令拿来调度的数据被称作操作数,指令执行时要有一个或者多个操作数,操作数被调用又要找到存放的位置。
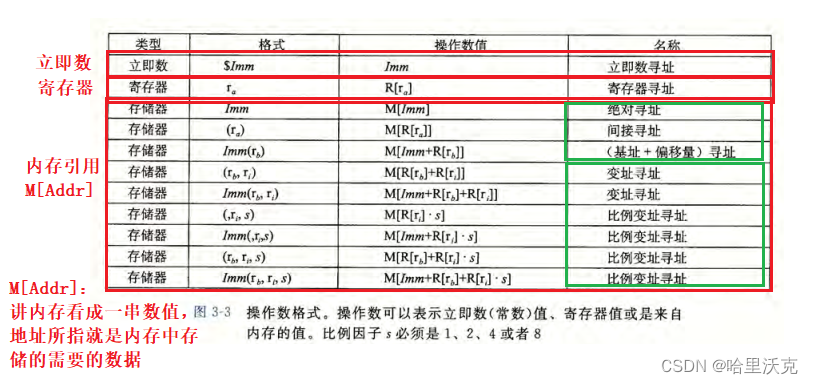
不同操作数存储的位置不同,分为三种类型:
1.立即值:这种数值前面加有$符号,指的是该数值是直接调用的
2.寄存器:该类数据可以理解为被寄存器保存,寄存器中的数就是所指
3.内存引用:它是通过计算大小,找到内存里对应的数值
接下来就是怎么找的问题了 --- 寻址模式
针对立即数$Imm:其实只要理解,指令本身就是要的数据
针对寄存器R[ra]:寄存器中的数值就是所需的数据,寄存器存放了该数据
解释一下R[ra]:就是把cpu里一堆寄存器看成一个数组,第ra就是所指向的那个寄存器
为了下面的讨论,我们需要解释其他几个数的含义:
Imm:就是某个数;R[rb]:就是基址寄存器,它用来存放偏移量的;R[ri]:就是变址寄存器
针对内存引用就比较麻烦了
先讨论第一个绿色框框:
1.绝对寻址,就是在内存里通过Imm这个立即数直接找到内存里对应位置的数值
2.间接寻址:先拿出寄存器里存储的数,这个拿去来的数再到对应的内存找值
3.寻址:就是先有一个数,对该数进行偏移,加起来的数就是内存的真正指向
讨论第二个绿色框框:
变址寻址必须有R[ri](也就是变址寄存器),通过变址寄存器可以描述一个数组的地址
注意:s必须是1,2,4,8。因为计算机的数据就是这些基本类型的倍数。
3.1.3数据传输
已经知道如何找到数据,但是指令是一些数与另一些数建立关系,所有我们还得知道如何传送数据
传送一个大小给另一个大小,是存在方向的,那么我们清楚了其实必须有一个源头有一个目的,而方向便是源头给目的。针对这个原因,指令也有必须描述传送的理由
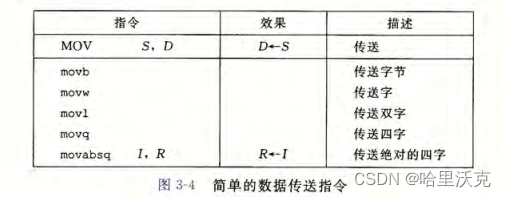
数据传送指令---MOV类(将数据从源位置复制到目的位置)
源操作数:立即数,寄存器,内存都可以
目的操作数(必须有一个位置):寄存器,内存
特别的,内存不能直接传给内存,中间需要寄存器过渡
1.截取或者同类传送,以及32位传64位
前面说过32位数据传送要把寄存器前面32位变成0哦
扩展传送
2.前面的位置扩展为0
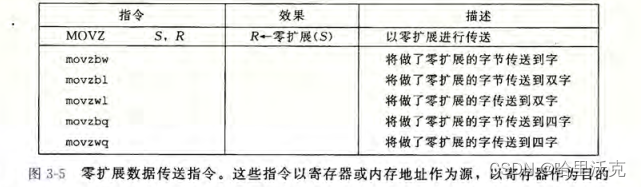
3.前面的位置扩展为符号位
~不难发现,其实指令的确定跟目的的大小有关;其次,送到内存,关键看源数值的位数。

3.1.4压入弹出栈数据
之前说过,栈区会在函数执行时通过扩容或者释放空间进行函数调用。而如何使得栈帧大小变化呢?压入和弹出栈的指令就是关键。
我们知道,栈是向下生长的,push和pop指令都是针对栈顶而言,也就是对最下面的位置进行操作。push就是压入,pop就是弹出。
%rsp指明的是栈顶的位置,它是push和pop改变的值,这个值能让我们确定栈顶在哪。
push和pop的一般步骤:先将%rsp的位置偏移到预设处,再进行压入数据或者弹出数据。

3.2.算术和逻辑操作
进行数据计算的指令符操作。
以下为要介绍的指令:
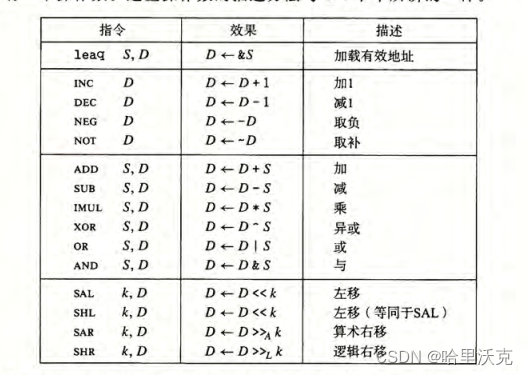
3.2.1.加载有效地址
需要与mov甄别以下
1.movl (%rax , %rcx ,4) %eax 指的是将内存里的数给寄存器
2.leaq (%rax , %rcx ,4) %rax 将这个地址(也就是(%rax , %rcx ,4)得到本身作为地址)传给寄存器。故在图中标记为&S,意思就是把S的地址加载给D。
3.因为计算的就是引用本身的数,那么设计者把leaq设计为可用于计算的指令,方便计算出数据,然后直接给寄存器,说明结果。
3.2.2.一元和二元操作
一元操作:++ -- 之类的操作,操作数只有一个,这个操作数既是源操作数又是目的操作数
二元操作:+ - * / 之类,操作数有两个,源操作数与目的操作数计算后结果存于目的操作数
3.2.3.移位操作
移位量可以是一个立即数,也可以存在%cl单字节寄存器中
SAL/SHL:左移
SAR:符号位右移 SHR:逻辑右移
3.2.4特殊的算术操作
两个64位有符号或无符号整数相乘得到的乘积需要128位来表示。 x86-64 指令集对 128 位 数的操作提供有限的支持。 延续双字和四字的命名惯例,Intel把16字节的数称为八字.

3.3.控制
这是针对某个特定函数所设计的操作数
目前为止,我们只能实现直线型数据处理,但是接触过C语言就知道,处理问题有条件语句,循环语句,分支语句,这些语句都需要跳转到特定的位置才能进行执行。
3.3.1条件码
除了上面说的整数寄存器,CPU还维护着一组单位数的寄存器,他们用于记录最近一次算数或者逻辑运算的状态属性。

特别的,leaq指令不会对条件码进行改变,因为该指令用于计算地址,不需要进行逻辑判断
其他的算数和逻辑计算会影响条件码,使得后续CPU知道我们计算后的情况。
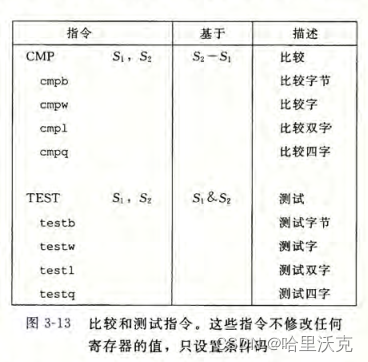
引入另外的操作数,这两个操作数只是用来通过计算改变条件码的,对其他的数不造成改变。
CMP通过减法得到大小关系转为条件码;TEXT通过&得到运算结果改变条件码
访问条件码:既然条件码是上文的结果,那么我们后续就必须得知道数据的内容,故我们要访问条件码。
条件码不会被直接读取,通常有三种方法用来使用:
1)可以根据条件码的某种组合,将一个字节设置为0或者1
2)可以条件跳转到程序的某个其他的部分
3)可以有条件地传送数据。
先介绍2、3,其实这两个不需要我们人为调用,当计算结果需要进行条件码判断时,系统自动提取数据进行判断。而1方法,其实是有一个SET指令,这个指令是一个大全,连接算数逻辑运算和条件码的桥梁,只要我们判断后,通过SET就能知道运算结果是怎么样的,这背后的原因就是SET帮我们访问了条件码的组合,返回给我们人能看的到的结果0/1。
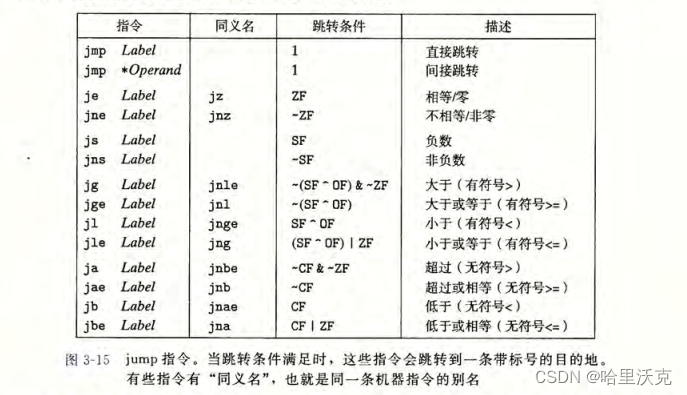
3.3.2跳转指令与其编码方式
跳转:与逐条执行不同,跳转使得程序切换到一个全新位置
跳转分为两类:jmp指令是无条件跳转
它可以是直接跳转,即跳转目标是作为指令的一部分编码的
也可以是间接跳转, 即跳转目标是从寄存器或内存位置中读出的
jmp为无条件跳转,其他都是需要条件才能跳转的


3.3.3条件语句
条件控制实现:
实现的思想很简单,就是通过控制进行选择,满足条件走哪边
判断时,先比较两个操作数,设置对应的条件码,通过条件码的信息,做出跳转的指令。
其实就是将所谓的if语句变成goto语句,最后汇编的代码也就根据goto语句的进行汇编。
以下为模板
--->


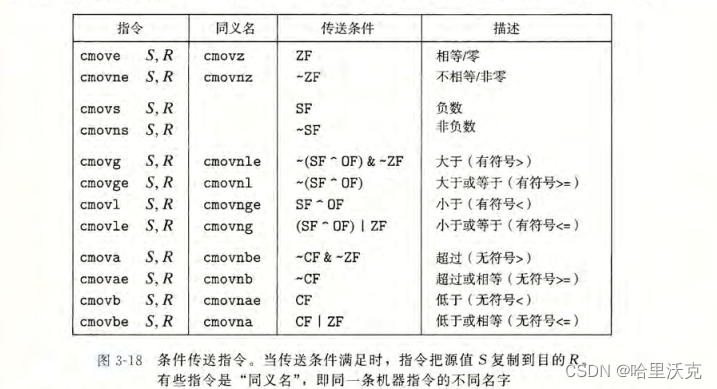
条件传送实现:
除了上面的条件控制,我们还可以通过数据的条件转移。
实现的思想,先将分支结果计算,最后比较条件里的数据获得条件码,指令选择要传送的代码。
以下是条件传送指令
但是并不是所有的条件跳转都可以用条件传送的指令来实现
它再判断之前就已经做了语法不允许的指令,所以我们可以知道条件传送的实现是基于条件之前就已经将不同分支的结果得到了,但是结果如果是需要条件先判断再能进行的话,那么这样就不允许用条件传送实现。


比较性能和gcc的实现底层
1.比较
相同代码都能跑,条件控制性能比条件传送的性能要差,这考虑到第四章流水线设计,我们只介绍简单的:首先条件控制中,机器遇到条件分支会去先猜测跳哪个条件,猜测耗费时间,每次猜测也不是100%的正确,返回去再判断又花费时间
2.推测花费的时间周期
如果执行函数:8周期;单单猜测条件:17.5周期;猜错了条件:19周期
计算:假设p为猜错的概率
周期公式为:
3.gcc的选择
条件传送如果遇到复杂的代码,算数的操作也降低很多的效率,而且条件传送有些情况不能执行,所以gcc选择条件控制实现条件跳转

3.3.4循环
C 语言提供了多种循环结构,即 do-while, while 和 for 汇编中没有相应的指令存在,可以用条件测试和跳转组合起来实现循环的效果。

3.3.5switch语句
switch(开关)语句可以根据一个整数索引值进行多重分支在处理具有多种可能结果的测试时,这种语句特别有用。不仅提高可读性,还通过跳转表使得代码更高效。
写好switch,汇编会开辟一个跳转表不同的条件对应不同的跳转,它以空间换时间,在每个分支都开辟直达的指令,从而不需要预先猜测,直接跳转即可。
