
java SPI机制
1.SPI介绍:
spi就是接口在调用方这边,调用方规定了接口的标准,实现方根据接口的规定来实现.将调用方和服务提供者实现解耦,能够提升程序的扩展性和可维护性.修改或者替换服务不需要修改调用方,只需要替换服务提供者即可.slf4j是经典的spi机制.
和api区别对比图如下:
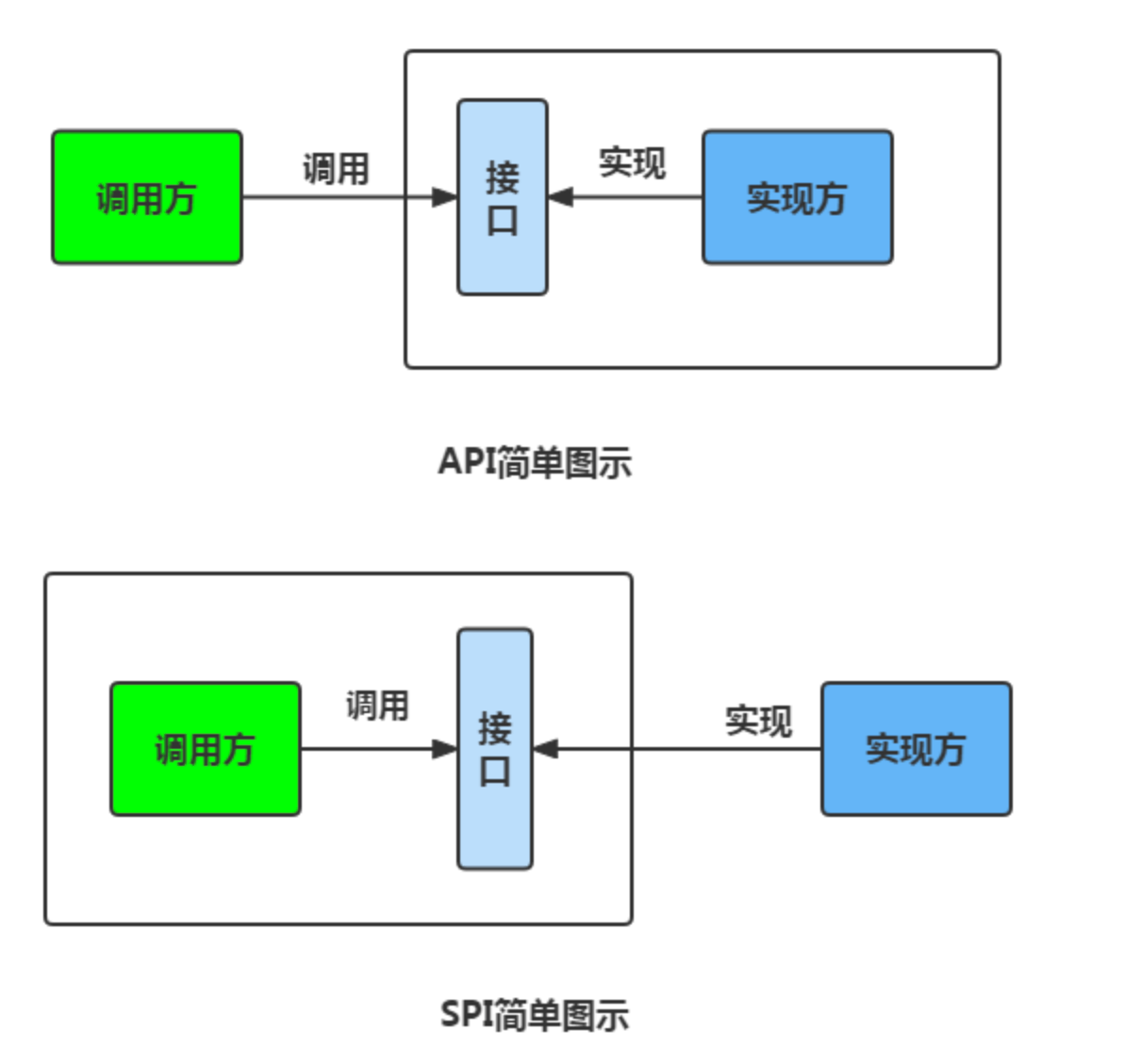
一般模块之间都是通过通过接口进行通讯,那我们在服务调用方和服务实现方(也称服务提供者)之间引入一个“接口”。
当实现方提供了接口和实现,我们可以通过调用实现方的接口从而拥有实现方给我们提供的能力,这就是 API ,这种接口和实现都是放在实现方的。
当接口存在于调用方这边时,就是 SPI ,由接口调用方确定接口规则,然后由不同的厂商去根据这个规则对这个接口进行实现,从而提供服务。
举个通俗易懂的例子:公司 H 是一家科技公司,新设计了一款芯片,然后现在需要量产了,而市面上有好几家芯片制造业公司,这个时候,只要 H 公司指定好了这芯片生产的标准(定义好了接口标准),那么这些合作的芯片公司(服务提供者)就按照标准交付自家特色的芯片(提供不同方案的实现,但是给出来的结果是一样的)。
Java 中的 SPI 机制就是在每次类加载的时候会先去找到 class 相对目录下的 META-INF 文件夹下的 services 文件夹下的文件,将这个文件夹下面的所有文件先加载到内存中,然后根据这些文件的文件名和里面的文件内容找到相应接口的具体实现类,找到实现类后就可以通过反射去生成对应的对象,保存在一个 list 列表里面,所以可以通过迭代或者遍历的方式拿到对应的实例对象,生成不同的实现。
所以会提出一些规范要求:文件名一定要是接口的全类名,然后里面的内容一定要是实现类的全类名,实现类可以有多个,直接换行就好了,多个实现类的时候,会一个一个的迭代加载。
2.ServiceLoader 具体实现
想要使用java的SPI机制是需要依赖ServiceLoader来实现的,ServiceLoader是位于package java.util包下的.是一种加载服务的实现工具.
是由final修饰的不可修改的类型的,同时实现了Iterable接口,之所以实现迭代器是方便后面通过迭代器在配置文件中找到全部符合接口模板要求的的实现类.
下图是一个模板实践类的结构,在META-INF路径下我们可以看到其services的文件名Logger是spi模板的名字.

主要流程:
1.通过URL工具类从jar包的/META-INF/services目录下找到对应的文件
2.读取这个文件的名称,找到对应的spi接口(在实现类的META-INF 目录下这个文件的名字就是要实现的spi接口的名字)
3.通过InputStream将文件里面的具体实现类的全类名读取出来.
4.根据全类名来判断跟spi的接口是否是同一类型(service.isAssignableFrom(clazz)),如果是同一类型则通过反射将对象创建出来对应实例的对象.
5.将构造出来的实例对象添加到provicers的列表中.
package edu.jiangxuan.up.service;import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.lang.reflect.Constructor;
import java.net.URL;
import java.net.URLConnection;
import java.util.ArrayList;
import java.util.Enumeration;
import java.util.List;public class MyServiceLoader {// 对应的接口 Class 模板private final Class service;// 对应实现类的 可以有多个,用 List 进行封装private final List providers = new ArrayList<>();// 类加载器private final ClassLoader classLoader;// 暴露给外部使用的方法,通过调用这个方法可以开始加载自己定制的实现流程。public static MyServiceLoader load(Class service) {return new MyServiceLoader<>(service);}// 构造方法私有化private MyServiceLoader(Class service) {this.service = service;this.classLoader = Thread.currentThread().getContextClassLoader();doLoad();}// 关键方法,加载具体实现类的逻辑private void doLoad() {try {// 读取所有 jar 包里面 META-INF/services 包下面的文件,
//这个文件名就是接口名,然后文件里面的内容就是具体的实现类的路径加全类名Enumeration urls = classLoader.getResources("META-INF/services/" + service.getName());// 挨个遍历取到的文件while (urls.hasMoreElements()) {// 取出当前的文件URL url = urls.nextElement();System.out.println("File = " + url.getPath());// 建立链接URLConnection urlConnection = url.openConnection();urlConnection.setUseCaches(false);// 获取文件输入流InputStream inputStream = urlConnection.getInputStream();// 从文件输入流获取缓存BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(inputStream));// 从文件内容里面得到实现类的全类名String className = bufferedReader.readLine();while (className != null) {// 通过反射拿到实现类的实例Class clazz = Class.forName(className, false, classLoader);// 如果声明的接口跟这个具体的实现类是属于同一类型,(可以理解为Java的一种多态,接口跟实现类、父类和子类等等这种关系。)则构造实例if (service.isAssignableFrom(clazz)) {Constructor constructor = (Constructor) clazz.getConstructor();S instance = constructor.newInstance();// 把当前构造的实例对象添加到 Provider的列表里面providers.add(instance);}// 继续读取下一行的实现类,可以有多个实现类,只需要换行就可以了。className = bufferedReader.readLine();}}} catch (Exception e) {System.out.println("读取文件异常。。。");}}// 返回spi接口对应的具体实现类列表public List getProviders() {return providers;}
}
其实不难发现,SPI 机制的具体实现本质上还是通过反射完成的。即:我们按照规定将要暴露对外使用的具体实现类在 META-INF/services/ 文件下声明。
通过 SPI 机制能够大大地提高接口设计的灵活性,但是 SPI 机制也存在一些缺点,比如:
- 遍历加载所有的实现类,这样效率还是相对较低的;
- 当多个
ServiceLoader同时load时,会有并发问题。
参考资料地址:
Java SPI 机制详解 | JavaGuide(Java面试+学习指南)