
招标网站信息爬取
目标网站
某采购与招标网
代码链接code-repo
准备工作
参考博客[1],使用谷歌浏览器的开发者工具,提取http的表单信息。
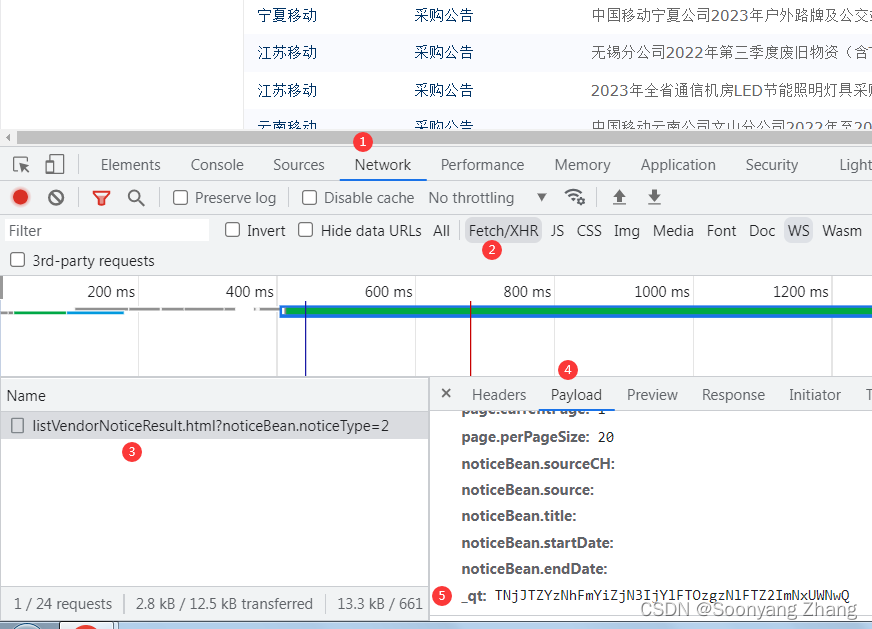
http post 中的表单信息,需要含有_qt信息。网站使用_qt做反爬虫措施。_qt由服务器返回,在不同的会话中,值是变化的。如果缺少_qt的信息,post的返回状态码是403。
在会话建立后,当客户端发送http get信息后,返回的页面中含有_qt的信息。主页另存为html,用文本编辑工具打开,可以看到_qt。
$.ajax({type : "POST",url : url,cache : false,processData : true,data : formData+ /*TZYz*/"&"//"/*"///'"'*//*0!caigou8*/+'_'/*JTZY*/+'q'/*ZYzNh5*/+'t'/*zNhFm076*/+'='/**/+//"/*"//*//*NhFmYiZj5"*/'TNjJTZYzNhFmYi'+/*"*'mYi5*///"/*JTZY*/'ZjN3IjYlFTOzgzNlFTZ2ImNxUWNwQ'///*ANjJTZYzNhFJyu*/,success : function(responseData) {$("#searchResult").html(responseData);if ($("#totalRecordNum").val() == 0) {var msg="查无结果!";$("#searchResult").html(msg);} else {$("#searchResult").html(responseData);}$('body').loadingmask('close');}});
可以看到javascript中添加了一些注释,做了混淆。本项目中提取_qt值的代码,通过字符串"0!caigou8"定位第一行,"success"定位最后一行。
def _parser_qt(text):f= io.StringIO(text)content=[]locate_caigou8=Falsewhile True:line=f.readline()if not line:breakelse:if locate_caigou8 is False and "0!caigou8" in line:locate_caigou8=Trueif locate_caigou8:if "success" in line:breakt=line.strip()t=_remove_annotation(t)if len(t)>0:content.append(t)length=len(content)qt=_strip_token(content[2],"'+")+_strip_token(content[3],"'+")return qt
获取网页索引信息
http post相关代码。如果想要请求其他省份的数据,请修form_data信息。
def request_page_index(session,cookie,qt,post_headers,page_index,retry=1,info_dir=None):success=Falseper_page_size=20province='YN'#https://zhuanlan.zhihu.com/p/31856224province_ch='云南'form_data={'page.currentPage':str(page_index),'page.perPageSize':str(per_page_size),'noticeBean.sourceCH':province_ch,'noticeBean.source':province,'noticeBean.title':'','noticeBean.startDate':'','noticeBean.endDate':'','_qt':qt}post_headers['cookie']=cookie#https://blog.csdn.net/weixin_51111267/article/details/124616848post_content=post_emit(session,post_url,post_headers,form_data,retry)if post_content is None:logging.warn("fail to download notice page {}".format(page_index))return successsuccess=Trueif info_dir:pathname=info_dir+province+"_"+str(page_index)+".txt"save_notice_page(pathname,post_content)return success 客户端发送http post消息后,服务器返回招标索引信息。对应的结果在浏览器中的展示如图。
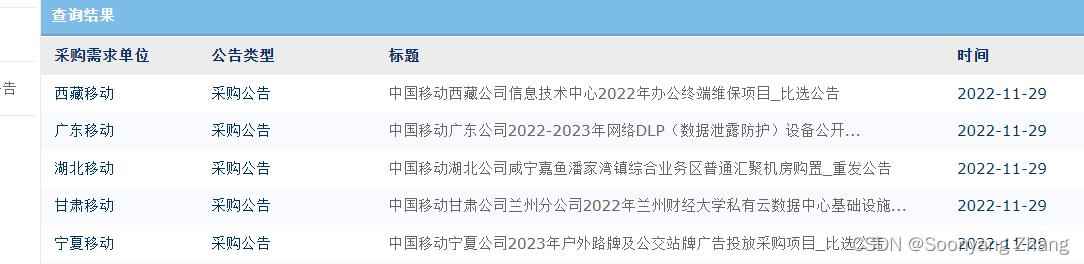
save_notice_page提取返回网页中包含的项目名称和id信息。处理获的结果可以在page-index文件夹中看到。
def save_notice_page(pathname,html_content):title2id=hp.get_onclick_info(html_content)fm.save_title2id(title2id,pathname)
html_parser.py
def get_onclick_info(html_content):soup = BeautifulSoup(html_content, 'lxml')tr_all=soup.find_all("tr")length=len(tr_all)dic={}for i in range(length):#{'class': [], 'onmousemove': 'cursorOver(this)', 'onmouseout': 'cursorOut(this)', 'onclick': "selectResult('901888')"}# type(attrs) is dictif tr_all[i].attrs and 'onclick' in tr_all[i].attrs:id=_parser_id(tr_all[i].attrs['onclick'])if len(id)>0:ahref=tr_all[i].find("a")if 'title' in ahref.attrs:dic.update({ahref.attrs['title']:id})elif len(ahref.contents)>0:dic.update({ahref.contents[0]:id})return dic
请求具体界面
根据page_index中保存的id信息,构造page_url,并下载网页内容,结构保存在resource文件夹中。
def download_notice_batch(index_list,resource_dir,suffix=".txt"):requests.packages.urllib3.util.ssl_.DEFAULT_CIPHERS += ':HIGH:!DH:!aNULL'for i in range(len(index_list)):user_agent=random.choice(ua_list)login_headers['User-Agent']=user_agentsession=requests.session()path_name=index_list[i]id2title=fm.extrac_id2title(path_name)pos2=path_name.rfind('.')pos1=path_name.rfind('/')name=path_name[pos1+1:pos2]new_path=resource_dir+name+'/'fm.mkdir(new_path)for item in id2title.items():id=item[0]page_url=url_base+id+""dest_name=new_path+id+suffixif open_page(session,page_url,login_headers,dest_name) is False:logging.warn("download failure {} {}".format(name,dest_name))session.close()
批量处理数据
按照甲方要求,提取数据。如需提取其他信息,请对parser_notice_content函数进行定制。
def process_page_batch(index_list,resource_dir,csv_name,suffix=".txt"):csv_f=open(csv_name,"w")delimiter='|'csv_f.write("index|page_id|title|no_tax|with_tax|duration|company|people|tel|\n")
运行代码:
github给出的连接中,给出了安装依赖。
1 获取网页索引
下载第1页到第10页,如果提示失败,请重新运行指令。结果保存在page-index文件夹。
python index_main.py --range=1:10
2 下载网页
根据page-index中的文件内容,下载网页通知。
python page-main.py
3 信息提取
python get_csv.py
结果保存在result.csv文件中。由于提取的信息中很有逗号,result.csv中使用符号|作为分隔符。使用excel打开前,请修改系统默认列表分割符,参考设置windows中的列表分隔符。excel打开csv之后,可以另存为xlsl文件。之后可以把系统默认列表分隔符改回去。
后记
之前请求网页索引,一直不知道怎么设置qt的值,总是得到403的响应。在这里一直卡了三天。解决qt之后,项目的完成又花了三天时间。
Reference:
[1]爬虫之爬取中国移动采购与招标网
[2]code-repo